

RÉSUMÉ
[IA & ML] Génération d’images par IA en 2026 : Guide pratique avec Stable Diffusion et Python
Découvrez comment générer des images époustouflantes avec l’IA en utilisant Stable Diffusion et Python.
Keywords: IA, Stable Diffusion, Python
TABLE DES MATIÈRES
1. Contexte : L’Ère de la Création Numérique Augmentée
2. Analyse Détaillée : Comprendre Stable Diffusion et son Écosystème Python
3. Résolution de Problèmes : Optimisation et Défis Techniques
4. Application Pratique : Générer Vos Premières Images par IA
5. Foire Aux Questions (FAQ)
6. Conclusion : L’Avenir de la Création Augmentée par l’IA
INTRODUCTION
Contexte : L’Ère de la Création Numérique Augmentée
En ce début d’année 2026, l’intelligence artificielle continue de redéfinir les frontières de la créativité et de la productivité. La génération d’images par IA, en particulier, a connu une croissance exponentielle, passant d’une curiosité technologique à un outil indispensable pour de nombreux professionnels et passionnés. Des artistes numériques aux designers graphiques, en passant par les développeurs de jeux vidéo et les marketeurs, la capacité à transformer une simple description textuelle en une œuvre visuelle complexe est devenue une compétence précieuse.
Au cœur de cette révolution se trouve Stable Diffusion, un modèle open source qui a démocratisé l’accès à la création d’images par IA. Contrairement à ses prédécesseurs et concurrents souvent propriétaires, Stable Diffusion offre une flexibilité sans précédent, permettant aux utilisateurs de l’adapter, de l’optimiser et de l’intégrer dans leurs propres flux de travail. Cet article, rédigé par Kwontenu, vise à vous fournir un guide pratique et détaillé pour maîtriser la génération d’images avec Stable Diffusion en utilisant Python, le langage de prédilection de l’IA.
Nous explorerons les fondements techniques de Stable Diffusion, ses avantages concurrentiels en 2026, et vous guiderons pas à pas à travers l’installation et l’utilisation de la bibliothèque Diffusers de Hugging Face. Attendez-vous à des exemples de code concrets, des astuces d’optimisation et une analyse approfondie des défis courants, le tout dans un langage clair et accessible.
POINT CLÉ
La génération d’images par IA, menée par des modèles comme Stable Diffusion, est devenue une compétence essentielle en 2026, offrant une liberté créative et une efficacité sans précédent dans de nombreux domaines professionnels.
ANALYSE
Analyse Détaillée : Comprendre Stable Diffusion et son Écosystème Python
Qu’est-ce que Stable Diffusion ?
Stable Diffusion est un modèle de diffusion latente développé par Stability AI. Contrairement aux modèles de diffusion traditionnels qui opèrent directement sur l’espace pixel des images, Stable Diffusion travaille dans un espace latent compressé. Cela réduit considérablement la complexité computationnelle et la quantité de VRAM requise, rendant le modèle accessible à un public plus large, même avec du matériel grand public (typiquement des GPU NVIDIA avec au moins 8 Go de VRAM).
Son fonctionnement peut être résumé en quelques étapes :
1. Encodage du texte : Un encodeur de texte (généralement basé sur CLIP) transforme votre prompt textuel en une représentation numérique (embedding).
2. Processus de diffusion : Un bruit aléatoire est généré dans l’espace latent. Le modèle de diffusion, conditionné par l’embedding textuel, effectue ensuite une série d’étapes de « dénaturation » (denoising) pour transformer ce bruit en une image cohérente.
3. Décodage : Un décodeur variationnel automatique (VAE) convertit la représentation latente finale en une image pixelisée haute résolution.
Les avantages de Stable Diffusion en 2026 sont multiples :
Avantages de Stable Diffusion
✓ Open Source : Code source et modèles pré-entraînés disponibles, permettant une personnalisation et une innovation communautaire.
✓ Flexibilité : Possibilité de fine-tuner le modèle avec des données spécifiques (ex: LoRA), de l’intégrer dans des applications diverses.
✓ Performance : Génération rapide d’images de haute qualité avec des ressources matérielles relativement modestes (par rapport à d’autres modèles fermés).
✓ Écosystème riche : Supporté par une vaste communauté de développeurs et d’artistes, avec de nombreux outils et extensions disponibles.
Inconvénients potentiels
✗ Complexité initiale : Nécessite une certaine compréhension technique pour l’installation et l’optimisation avancée.
✗ Qualité variable : La qualité des images générées dépend fortement de la qualité du prompt et des paramètres choisis.
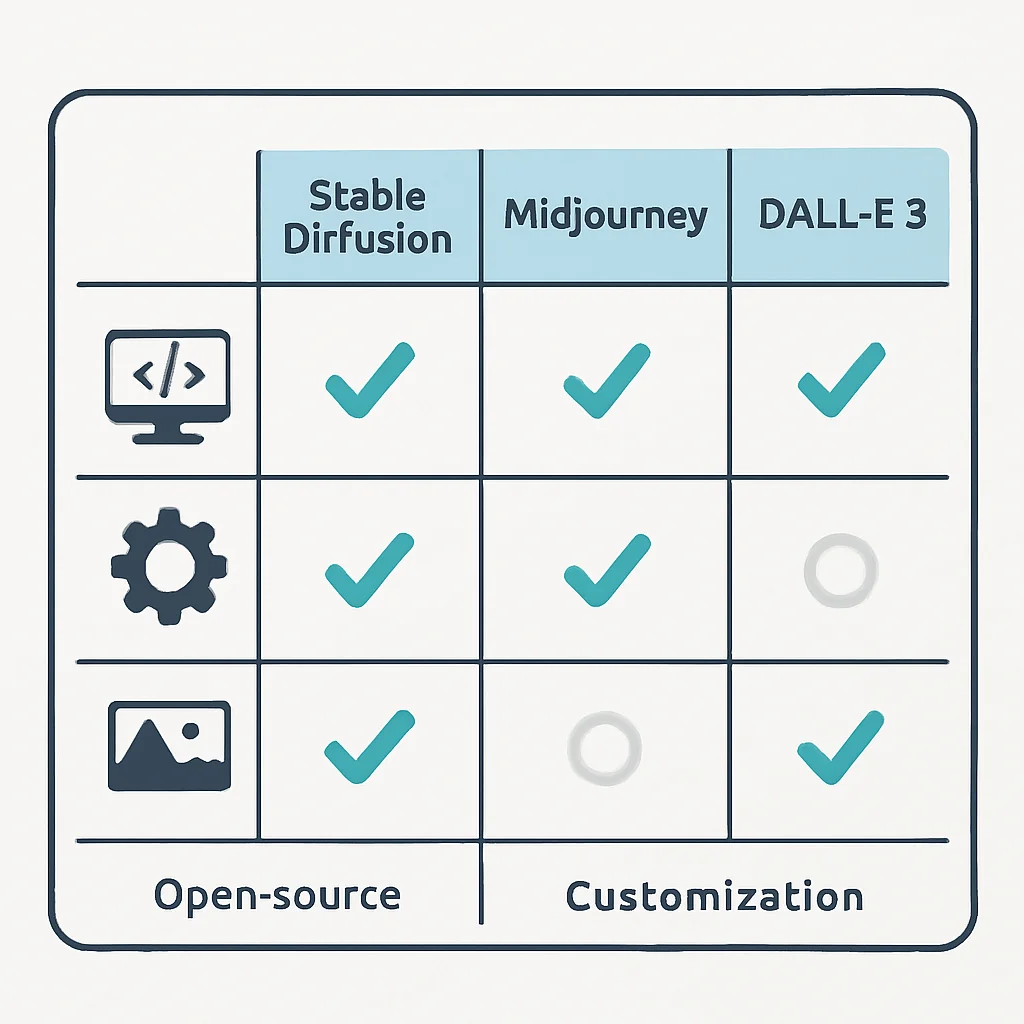
En comparaison avec des services propriétaires comme Midjourney ou DALL-E 3, Stable Diffusion se distingue par son approche open source. Alors que Midjourney excelle dans la génération d’art stylisé avec une interface simple et DALL-E 3 est réputé pour sa compréhension contextuelle des prompts complexes, Stable Diffusion offre la liberté totale de contrôle et de personnalisation. En 2026, l’écart de qualité visuelle entre ces modèles s’est réduit, et Stable Diffusion, en particulier avec ses versions améliorées (comme SDXL), rivalise très bien avec les leaders du marché sur de nombreux aspects, tout en offrant une flexibilité inégalée pour des cas d’utilisation spécifiques et des intégrations profondes.
POINT CLÉ
Stable Diffusion est un modèle de diffusion latente open source, performant et flexible, qui transforme le texte en image. Sa capacité à être personnalisé et intégré le rend particulièrement puissant, le distinguant des solutions propriétaires en 2026.
L’Intégration Python : Diffusers de Hugging Face
Pour interagir avec Stable Diffusion en Python, la bibliothèque Diffusers de Hugging Face est l’outil de choix. Elle fournit une API intuitive et bien documentée pour charger, exécuter et personnaliser des pipelines de diffusion. Hugging Face est devenu un acteur incontournable dans l’écosystème de l’IA, offrant des milliers de modèles pré-entraînés et des outils pour les utiliser facilement.
L’installation de Diffusers et de ses dépendances est simple. Vous aurez besoin de PyTorch, la principale bibliothèque de deep learning, et de transformers pour l’encodage du texte. Un GPU NVIDIA avec les pilotes CUDA installés est fortement recommandé pour des performances acceptables. Pour une expérience optimale en 2026, un GPU avec au moins 12 Go de VRAM (comme une RTX 3060 ou supérieure) est idéal, bien que 8 Go puissent suffire avec des optimisations.
EXPLICATION DU CODE
Ce bloc de code montre comment installer les bibliothèques Python nécessaires via pip. accelerate est recommandé pour l’optimisation des performances sur GPU.
pip install diffusers transformers accelerate torch torchvision --upgradeUne fois installée, Diffusers vous permet de charger un « pipeline », qui est une abstraction de haut niveau englobant tous les composants nécessaires à la génération d’images :
Pipeline : La séquence complète d’opérations, de l’entrée texte à l’image finale.
Scheduler : L’algorithme qui contrôle le processus de dénaturation (ex: EulerAncestralDiscreteScheduler, DDIMScheduler). Il influence la vitesse et la qualité.
Tokenizer et Text Encoder : Convertissent le prompt textuel en un format compréhensible par le modèle de diffusion.
UNet : Le réseau neuronal principal qui effectue la dénaturation dans l’espace latent.
VAE (Variational AutoEncoder) : Convertit les représentations latentes en images pixelisées.
POINT CLÉ
La bibliothèque Diffusers de Hugging Face est l’interface Python standard pour Stable Diffusion, simplifiant l’accès à des pipelines complexes et nécessitant PyTorch et un GPU compatible CUDA pour des performances optimales.
OPTIMISATION
Résolution de Problèmes : Optimisation et Défis Techniques
Travailler avec des modèles de deep learning, surtout pour la génération d’images, présente des défis techniques, principalement liés à la gestion des ressources matérielles. Les deux problèmes majeurs sont la consommation de mémoire (VRAM) et le temps de génération.
Gestion de la Mémoire (VRAM)
Les modèles de diffusion sont gourmands en VRAM. Si votre GPU ne dispose pas de suffisamment de mémoire dédiée, vous rencontrerez des erreurs « CUDA out of memory ». Heureusement, plusieurs stratégies d’optimisation existent pour Stable Diffusion en 2026 :
Consommation Excessive de VRAM
Les modèles Stable Diffusion, en particulier SDXL, peuvent facilement saturer la VRAM des GPU avec 8 Go ou moins, menant à des erreurs de mémoire et à l’incapacité de générer des images.
SOLUTION — Optimisation du Pipeline pour la VRAM
Utilisez le type de données fp16 (float16) pour les poids du modèle, qui réduit la mémoire de moitié sans perte significative de qualité. Activez l’offloading du CPU pour les composants inutilisés.
EXPLICATION DU CODE
Ce code configure le pipeline Stable Diffusion XL (SDXL) pour utiliser l’inférence en fp16 et déplacer les composants du modèle vers le CPU lorsqu’ils ne sont pas utilisés, réduisant ainsi la charge sur la VRAM.
import torch
from diffusers import DiffusionPipeline
# Charger le pipeline SDXL en fp16 pour une meilleure gestion de la VRAM
pipeline = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
torch_dtype=torch.float16,
use_safetensors=True,
variant="fp16"
)
# Activer l'offloading des modules du modèle vers le CPU
# Cela permet de charger les composants du modèle uniquement quand ils sont utilisés,
# libérant de la VRAM entre les étapes.
pipeline.enable_model_cpu_offload()
# Exemple d'utilisation (le prompt sera défini plus tard)
# image = pipeline("un chat astronaute", num_inference_steps=25).images[0]POINT CLÉ
L’optimisation de la VRAM est cruciale pour Stable Diffusion. L’utilisation de torch.float16 et l’offloading des modèles vers le CPU (enable_model_cpu_offload()) sont des techniques incontournables pour les GPU avec une VRAM limitée.
Vitesse de Génération
Le temps nécessaire pour générer une image peut varier de quelques secondes à plusieurs minutes, selon la complexité du prompt, le nombre d’étapes d’inférence, la taille de l’image et, bien sûr, la puissance de votre GPU. En 2026, la recherche sur les schedulers a permis des avancées significatives en termes de vitesse.
Temps de Génération Long
Des temps de génération élevés réduisent l’efficacité et la fluidité du processus créatif, surtout lors d’expérimentations avec différents prompts ou paramètres.
SOLUTION — Choix du Scheduler et Compilation Torch
Certains schedulers comme DPM++ 2M Karras ou Euler Ancestral sont connus pour leur efficacité. De plus, la compilation du modèle avec torch.compile (disponible depuis PyTorch 2.0) peut offrir des gains de performance significatifs.
EXPLICATION DU CODE
Cet exemple montre comment changer le scheduler du pipeline et comment utiliser torch.compile pour accélérer l’inférence. Notez que torch.compile nécessite PyTorch 2.0+.
from diffusers import DPM2MDiscreteScheduler
# ... (pipeline loaded as before) ...
# 1. Changer le scheduler pour un plus rapide
pipeline.scheduler = DPM2MDiscreteScheduler.from_config(pipeline.scheduler.config)
# 2. Compiler le modèle pour des gains de performance (nécessite PyTorch 2.0+)
# Attention: la première exécution après compilation peut être plus lente,
# mais les suivantes seront plus rapides.
if hasattr(torch, 'compile'):
pipeline.unet = torch.compile(pipeline.unet, mode="reduce-overhead", fullgraph=True)
# Vous pouvez aussi compiler d'autres composants comme le VAE si nécessaire
# pipeline.vae = torch.compile(pipeline.vae, mode="reduce-overhead", fullgraph=True)
# Maintenant, générez avec le scheduler rapide et le modèle compilé
# image = pipeline("un paysage futuriste sous la pluie", num_inference_steps=20).images[0]POINT CLÉ
Pour accélérer la génération d’images, expérimentez avec différents schedulers optimisés pour la vitesse et utilisez torch.compile de PyTorch 2.0+ pour des gains significatifs sur les modèles compatibles CUDA.
GUIDE PRATIQUE
Application Pratique : Générer Vos Premières Images par IA
Maintenant que nous avons couvert la théorie et les optimisations, passons à la pratique. Nous allons générer notre première image avec Stable Diffusion et Python.
Préparation de l’Environnement
Installer les dépendances
Assurez-vous que Python (version 3.8+) est installé et exécutez la commande d’installation des bibliothèques que nous avons vue précédemment. Il est recommandé d’utiliser un environnement virtuel.
Vérifier la configuration GPU
Confirmez que vos pilotes NVIDIA sont à jour et que CUDA est correctement configuré pour PyTorch. Vous pouvez le vérifier en exécutant import torch; print(torch.cuda.is_available()) dans votre interpréteur Python. Cela devrait retourner True.
Exemple Simple : Texte à Image
Le cœur de la génération d’images par IA réside dans le « prompt engineering » : l’art de rédiger des descriptions textuelles efficaces pour guider le modèle. Un bon prompt est clair, descriptif et peut inclure des styles artistiques, des détails sur l’éclairage, la composition, etc. En 2026, des prompts complexes avec des centaines de mots sont monnaie courante pour des résultats précis.
EXPLICATION DU CODE
Ce code initialise un pipeline Stable Diffusion (ici, nous utilisons le modèle de base SDXL pour sa qualité) et génère une image à partir d’un prompt. L’image résultante est ensuite sauvegardée sous forme de fichier PNG.
import torch
from diffusers import DiffusionPipeline
# 1. Charger le pipeline (vous pouvez choisir un autre modèle ou une version fine-tunée)
# Utilisons SDXL pour une meilleure qualité en 2026
pipeline = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
torch_dtype=torch.float16, # Toujours utiliser fp16 pour l'optimisation VRAM
use_safetensors=True,
variant="fp16"
)
# 2. Déplacer le pipeline vers le GPU et activer l'offloading CPU si nécessaire
pipeline.to("cuda")
pipeline.enable_model_cpu_offload()
# 3. Définir le prompt
prompt = "Un chat cyborg cyberpunk avec des yeux laser, assis sur un trône de serveurs, ambiance néon, éclairage dramatique, haute résolution, style artstation, détails complexes, 8k"
# Vous pouvez aussi ajouter un prompt négatif pour guider le modèle loin de certains éléments
negative_prompt = "basse qualité, flou, déformé, moche, watermark, texte, signature"
# 4. Générer l'image
# num_inference_steps: nombre d'étapes de dénaturation (plus il y en a, plus c'est détaillé, mais plus c'est long)
# guidance_scale: à quel point le modèle doit suivre le prompt (valeurs typiques: 7.0-10.0)
image = pipeline(
prompt=prompt,
negative_prompt=negative_prompt,
num_inference_steps=30,
guidance_scale=8.5
).images[0]
# 5. Sauvegarder l'image
image.save("chat_cyborg_kwontenu.png")
print("Image générée et sauvegardée sous chat_cyborg_kwontenu.png")Quelques paramètres clés à comprendre :
num_inference_steps : Représente le nombre d’étapes que le modèle prendra pour raffiner l’image du bruit vers le résultat final. Plus le nombre est élevé (généralement entre 20 et 50), plus l’image est détaillée, mais plus le temps de génération est long. Pour la plupart des cas, 25 à 30 étapes sont un bon équilibre.
guidance_scale (ou CFG Scale) : Détermine l’adhérence du modèle à votre prompt. Une valeur plus élevée (ex: 9-12) rendra l’image plus fidèle au prompt, mais peut la rendre moins créative ou plus « dure ». Une valeur plus basse (ex: 5-7) laisse plus de liberté au modèle, potentiellement pour des résultats plus originaux. Les valeurs typiques varient entre 7 et 10.
negative_prompt : Un prompt négatif est une description de ce que vous NE voulez PAS voir dans votre image. C’est un outil très puissant pour améliorer la qualité et éviter les artefacts indésirables.
POINT CLÉ
Le « prompt engineering » est essentiel pour obtenir des résultats de qualité. Un prompt détaillé, combiné à un negative_prompt efficace et des paramètres bien ajustés (num_inference_steps, guidance_scale), est la clé de la réussite en génération d’images par IA.

Techniques Avancées : Inpainting, Outpainting, ControlNet
Au-delà de la simple génération texte-à-image, Stable Diffusion, via la bibliothèque Diffusers, offre des capacités avancées qui étendent considérablement les possibilités créatives :
Fonctionnalités Avancées de Stable Diffusion
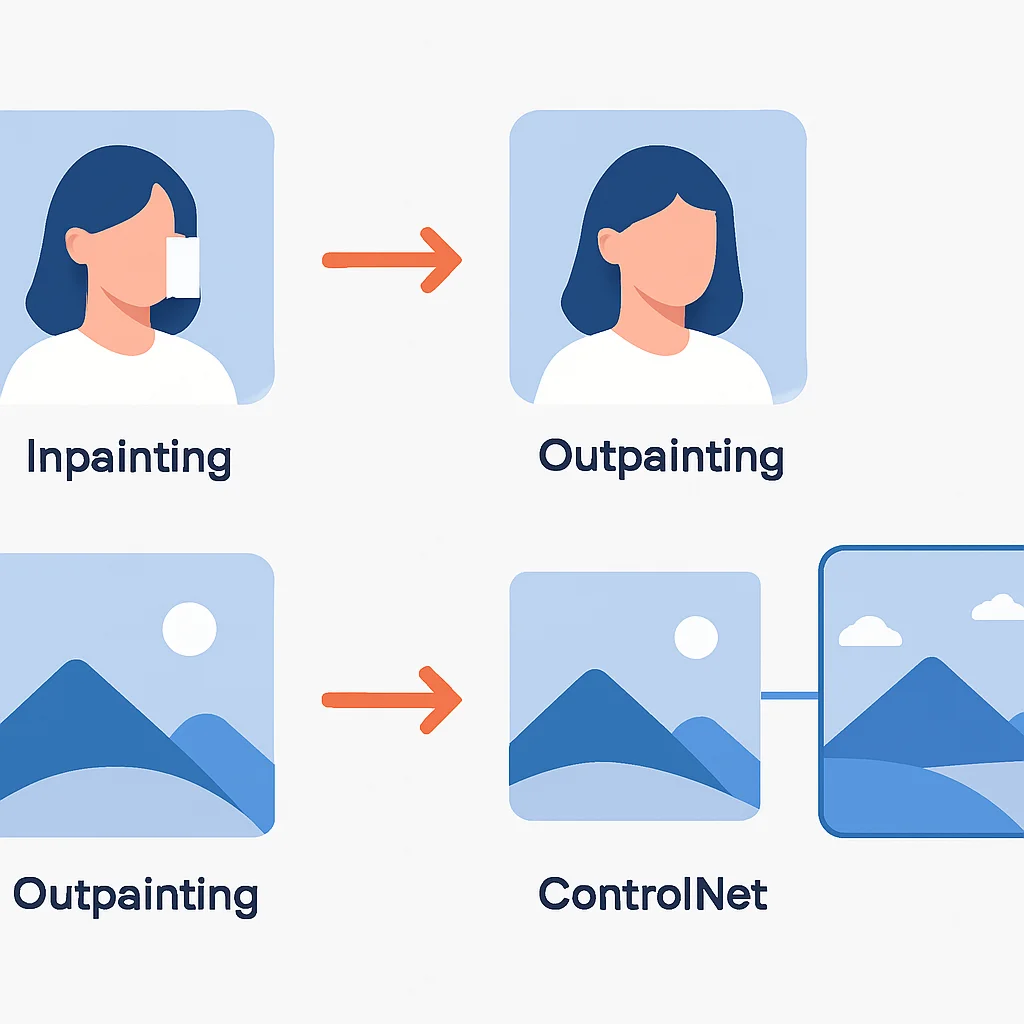
Inpainting : Permet de modifier ou de remplacer des parties spécifiques d’une image existante en utilisant un masque. Idéal pour retoucher des éléments ou ajouter de nouveaux objets de manière cohérente.
Outpainting : Étend une image au-delà de ses frontières originales, créant de nouveaux éléments qui s’intègrent naturellement au contenu existant. Très utile pour l’agrandissement de scènes ou la création de panoramas.
ControlNet : Un ajout révolutionnaire qui offre un contrôle précis sur la structure spatiale de l’image générée. Vous pouvez utiliser des cartes de profondeur, des croquis, des poses humaines (OpenPose) ou des cartes Canny pour guider la génération, garantissant que l’IA respecte une composition ou une pose spécifique. En 2026, ControlNet est un pilier pour la création de contenu contrôlé.
Ces techniques ouvrent la porte à des applications professionnelles avancées, de la conception architecturale à la modélisation de personnages 3D, en passant par la création d’assets pour des jeux vidéo. L’apprentissage de ces outils est un investissement précieux pour tout créateur numérique en 2026.
Foire Aux Questions (FAQ)
Q. Quel est le principal avantage de Stable Diffusion par rapport à d’autres générateurs d’images par IA en 2026 ?
Le principal avantage de Stable Diffusion réside dans sa nature open source et sa flexibilité. Contrairement aux modèles propriétaires comme Midjourney ou DALL-E 3, Stable Diffusion permet une personnalisation approfondie, une intégration facile dans des applications tierces et un contrôle total sur le processus de génération, ce qui est crucial pour les développeurs et les artistes cherchant des solutions sur mesure.
Q. Quels sont les prérequis matériels pour utiliser Stable Diffusion avec Python ?
Pour une utilisation fluide de Stable Diffusion avec Python, un GPU NVIDIA avec au moins 8 Go de VRAM est recommandé. Idéalement, 12 Go ou plus (comme une RTX 3060 ou supérieure) sont préférables, surtout pour des modèles plus grands comme SDXL ou des résolutions d’image élevées. Vous aurez également besoin de Python 3.8+ et des pilotes CUDA à jour.
Q. Qu’est-ce que le « prompt engineering » et pourquoi est-il important ?
Le « prompt engineering » est l’art de rédiger des descriptions textuelles (prompts) efficaces et détaillées pour guider un modèle de génération d’images par IA. Il est crucial car la qualité et la pertinence de l’image générée dépendent directement de la clarté et de la richesse sémantique du prompt. Un bon prompt permet d’obtenir des résultats précis et créatifs, tandis qu’un prompt vague peut donner des images aléatoires ou de mauvaise qualité.
Q. Comment optimiser la consommation de VRAM lors de la génération d’images ?
Pour optimiser la consommation de VRAM, utilisez des techniques comme l’inférence en torch.float16 (précision semi-précise), activez l’offloading des modèles vers le CPU (enable_model_cpu_offload()) et réduisez la taille des images générées si votre GPU est très limité. Ces méthodes réduisent l’empreinte mémoire du modèle sur le GPU.
CONCLUSION
Conclusion : L’Avenir de la Création Augmentée par l’IA
Nous avons parcouru un chemin passionnant, du concept de la génération d’images par IA à la mise en œuvre pratique avec Stable Diffusion et Python. En 2026, l’IA générative n’est plus une technologie de niche, mais un courant dominant qui transforme la manière dont nous créons, imaginons et interagissons avec le contenu visuel. Stable Diffusion, avec son modèle open source et sa communauté dynamique, est à l’avant-garde de cette transformation, offrant des outils puissants et accessibles à tous.
Nous avons vu comment installer et configurer votre environnement, comment générer vos premières images avec des prompts précis, et comment surmonter les défis techniques courants liés à la VRAM et à la vitesse de génération. Les techniques avancées comme l’inpainting, l’outpainting et surtout ControlNet, démontrent l’étendue du contrôle créatif que l’on peut désormais exercer sur les modèles d’IA.
L’avenir de la création numérique est sans aucun doute augmenté par l’IA. Pour les professionnels et les amateurs, maîtriser des outils comme Stable Diffusion ne consiste pas à remplacer la créativité humaine, mais à l’amplifier. L’IA devient un collaborateur, un assistant capable de concrétiser des visions à une vitesse et une échelle auparavant inimaginables. Kwontenu s’engage à continuer de vous guider à travers ces innovations, en décryptant la complexité technique pour la rendre accessible.
POINT CLÉ
L’IA générative, et Stable Diffusion en particulier, est un catalyseur pour la créativité humaine en 2026. Elle offre des outils puissants pour amplifier nos capacités, plutôt que de les remplacer, et ouvre la voie à des innovations visuelles sans précédent.
Merci de votre lecture !
Nous espérons que ce guide pratique vous a éclairé sur le potentiel de la génération d’images par IA avec Stable Diffusion et Python en 2026. L’exploration de ce domaine est infinie, et chaque jour apporte de nouvelles découvertes.
Des questions ? Laissez un commentaire ou explorez d’autres articles sur Kwontenu.com pour approfondir vos connaissances en IA et ML !