

RÉSUMÉ
Prévisions de séries temporelles en 2026 : Guide pratique avec Python, Prophet et ARIMA
Maîtrisez les prévisions de séries temporelles en Python avec ce guide pour des modèles précis.
Keywords: Python, Séries temporelles, Prophet
TABLE DES MATIÈRES
1. Contexte : L’Art et la Science de la Prévision
2. Fondamentaux des Séries Temporelles
3. ARIMA : Les Bases et l’Implémentation en Python
4. Prophet : La Simplicité de Facebook pour des Prévisions Robustes
5. Analyse Comparative : ARIMA vs. Prophet
6. Défis et Solutions Courantes en Prévision
7. Application Pratique Avancée : Optimisation et Évaluation
8. FAQ
9. Conclusion : Anticiper l’Avenir avec Confiance
INTRODUCTION
1. Contexte : L’Art et la Science de la Prévision
Dans le monde en constante évolution de 2026, la capacité à anticiper l’avenir n’est plus un luxe, mais une nécessité stratégique pour toute entreprise ou organisation. Que ce soit pour prévoir les ventes de produits, estimer le trafic d’un site web, optimiser la gestion des stocks, ou même prédire la propagation d’une maladie, les prévisions de séries temporelles jouent un rôle crucial. Elles permettent de transformer l’incertitude en décisions éclairées, offrant un avantage concurrentiel significatif.
Les séries temporelles sont des séquences de points de données indexées dans le temps, et leur analyse est un domaine fascinant de la science des données. Comprendre les tendances passées et les motifs récurrents permet de projeter ces dynamiques dans le futur. Cependant, la modélisation de ces séries peut être complexe, car elles sont souvent influencées par des facteurs multiples : saisonnalité, tendance, événements externes, et bruit aléatoire.
Heureusement, l’écosystème Python offre une panoplie d’outils puissants et accessibles pour aborder ce défi. Parmi eux, deux méthodes se distinguent par leur popularité et leur efficacité : ARIMA (AutoRegressive Integrated Moving Average) et Prophet, la bibliothèque développée par Facebook. Alors que ARIMA est un pilier statistique classique, Prophet représente une approche plus moderne, conçue pour gérer des séries temporelles avec une saisonnalité forte et des jours fériés, souvent rencontrées dans les données d’affaires.
Ce guide pratique, conçu pour les experts comme pour les novices en science des données, vous plongera dans les arcanes de la prévision de séries temporelles en Python. Nous démystifierons le jargon technique, fournirons des explications claires et des exemples concrets, et vous montrerons comment implémenter ces modèles étape par étape. Préparez-vous à transformer vos données historiques en prévisions fiables pour l’année 2026 et au-delà !
POINT CLÉ
La prévision de séries temporelles est essentielle en 2026 pour la prise de décision stratégique. Python, avec des outils comme ARIMA et Prophet, offre des solutions robustes pour analyser les tendances passées et projeter l’avenir avec confiance.
COMPRENDRE
2. Fondamentaux des Séries Temporelles
Avant de plonger dans les modèles, il est crucial de comprendre ce qu’est une série temporelle et quels sont ses composants. Une série temporelle est une séquence de données collectées à des intervalles de temps successifs et réguliers. Ces données peuvent représenter presque tout ce qui change avec le temps : le cours d’une action, la température quotidienne, le nombre de visiteurs sur un site web, ou la consommation d’énergie.
Les Composants Clés d’une Série Temporelle
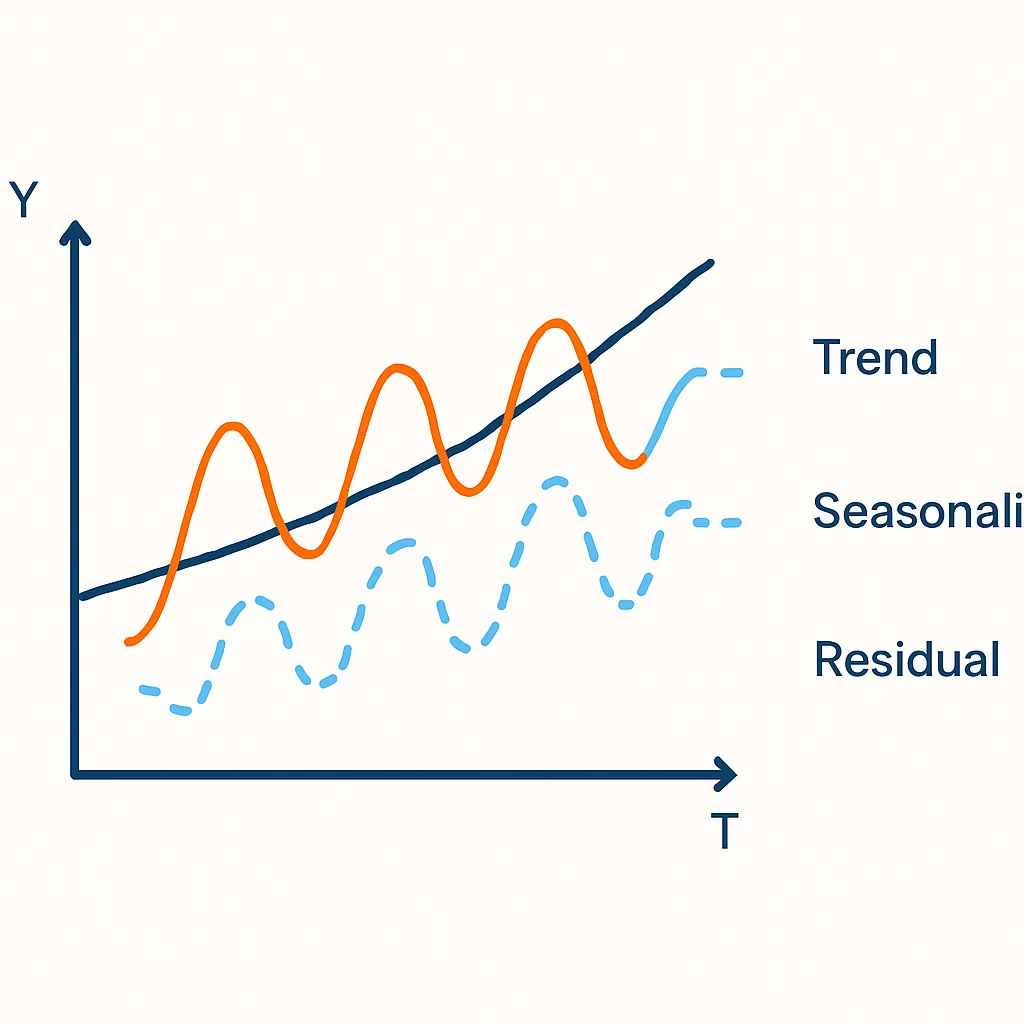
Typiquement, une série temporelle peut être décomposée en trois ou quatre composants principaux :
- Tendance (Trend) : C’est le mouvement à long terme de la série, qui indique si la série augmente, diminue ou reste stable sur une longue période. Par exemple, une croissance constante des ventes sur plusieurs années.
- Saisonnalité (Seasonality) : Il s’agit de motifs qui se répètent à des intervalles de temps fixes et connus, comme les pics de ventes pendant les fêtes de fin d’année ou les baisses de trafic web le week-end.
- Cycle (Cycle) : Similaire à la saisonnalité mais sur des périodes plus longues et moins régulières (par exemple, des cycles économiques de 5 à 10 ans). Certains modèles les englobent dans la tendance ou le résidu.
- Résidu (Residual ou Noise) : C’est la partie de la série qui reste après avoir retiré la tendance et la saisonnalité. Elle représente les fluctuations aléatoires ou imprévisibles.
L’Importance de la Stationnarité
Un concept fondamental pour de nombreux modèles statistiques de séries temporelles, notamment ARIMA, est la stationnarité. Une série temporelle est dite stationnaire si ses propriétés statistiques (moyenne, variance, autocorrélation) ne changent pas au fil du temps. En d’autres termes, elle n’a pas de tendance, sa variance est constante et ses motifs saisonniers ne varient pas en amplitude.
Pourquoi est-ce important ? Parce que de nombreux modèles statistiques supposent que les données sont stationnaires pour que les prévisions soient valides. Si une série n’est pas stationnaire, des transformations (comme la différenciation, c’est-à-dire calculer la différence entre une observation et la précédente) sont souvent appliquées pour la rendre stationnaire. C’est le « I » (Integrated) dans ARIMA.
Cas d’Utilisation Concrets en 2026
Les applications des prévisions de séries temporelles sont vastes et impactent de nombreux secteurs en 2026 :
- Retail et E-commerce : Prévision des ventes pour optimiser la gestion des stocks, planifier les promotions et améliorer la logistique. Par exemple, prévoir les ventes de smartphones pour le Black Friday 2026.
- Finance : Prédiction des cours boursiers, des taux de change, ou de la demande de crédits pour la gestion des risques et les stratégies d’investissement. Un fonds d’investissement pourrait utiliser ces modèles pour anticiper les mouvements du marché des cryptomonnaies.
- Énergie : Prévision de la consommation d’électricité ou de gaz pour optimiser la production et la distribution, évitant ainsi les pannes ou les surproductions. Les fournisseurs d’énergie utilisent ces modèles pour anticiper les pics de consommation lors des vagues de chaleur ou de froid.
- Santé : Prédiction de la propagation de maladies, de la demande de lits d’hôpital ou de médicaments pour une meilleure planification des ressources. Les autorités sanitaires pourraient modéliser l’évolution d’une épidémie saisonnière pour mieux allouer les vaccins.
POINT CLÉ
La décomposition d’une série temporelle en tendance, saisonnalité et résidu est fondamentale. La stationnarité est une propriété clé pour de nombreux modèles traditionnels, nécessitant souvent des transformations des données.
MODÉLISATION ARIMA
3. ARIMA : Les Bases et l’Implémentation en Python
ARIMA, acronyme de AutoRegressive Integrated Moving Average, est l’un des modèles les plus établis et largement utilisés pour la prévision de séries temporelles. Il combine trois composantes principales pour capturer différentes dynamiques des données.
Composantes du Modèle ARIMA (p, d, q)
- AR (AutoRégressif) — paramètre
p: La composante autorégressive indique que la valeur actuelle de la série dépend linéairement de ses propres valeurs passées. Le paramètrepreprésente le nombre de termes autorégressifs (nombre d’observations passées à inclure dans le modèle). - I (Intégré) — paramètre
d: La composante intégrée fait référence à la différenciation des observations brutes pour rendre la série temporelle stationnaire. Le paramètredest l’ordre de différenciation (le nombre de fois où les observations brutes sont différenciées). - MA (Moyenne Mobile) — paramètre
q: La composante moyenne mobile indique que la valeur actuelle de la série dépend des erreurs de prévision passées (les résidus des prévisions précédentes). Le paramètreqreprésente le nombre de termes de moyenne mobile.
Un modèle ARIMA est donc noté ARIMA(p, d, q).
Processus de Modélisation ARIMA
La construction d’un modèle ARIMA suit généralement ces étapes :
- 1. Analyse et Visualisation : Examiner la série temporelle pour identifier la tendance, la saisonnalité et la stationnarité.
- 2. Rendre la série stationnaire : Appliquer des différenciations (déterminer
d) jusqu’à ce que la série soit stationnaire. Des tests comme le test de Dickey-Fuller augmenté (ADF) peuvent aider. - 3. Identification des ordres p et q : Utiliser les fonctions d’autocorrélation (ACF) et d’autocorrélation partielle (PACF) des résidus pour déterminer les ordres
petq. - 4. Estimation du modèle : Entraîner le modèle ARIMA avec les ordres (p, d, q) choisis.
- 5. Diagnostic et Validation : Vérifier les résidus du modèle pour s’assurer qu’ils sont du bruit blanc (non corrélés, moyenne nulle, variance constante). Si ce n’est pas le cas, réajuster les ordres.
Exemple Pratique avec statsmodels en Python
Nous allons simuler des données simples pour illustrer l’utilisation de la bibliothèque statsmodels en Python pour un modèle ARIMA. Imaginons une série temporelle mensuelle de ventes sur quelques années.
EXPLICATION DU CODE
Ce code simule une série temporelle avec une tendance et une saisonnalité, puis applique une différenciation pour la rendre stationnaire. Ensuite, il utilise le module ARIMA de statsmodels pour ajuster un modèle ARIMA et générer des prévisions.
import pandas as pd
import numpy as np
from statsmodels.tsa.arima.model import ARIMA
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
# 1. Génération de données simulées (ventes mensuelles)
np.random.seed(42)
dates = pd.date_range(start='2020-01-01', periods=72, freq='MS') # 6 ans de données
data = 100 + np.arange(72) * 2 + np.sin(np.arange(72) * 2 * np.pi / 12) * 50 + np.random.normal(0, 10, 72)
sales_data = pd.Series(data, index=dates)
# Visualisation des données brutes
# plt.figure(figsize=(12, 6))
# plt.plot(sales_data)
# plt.title('Série Temporelle des Ventes Simulées')
# plt.xlabel('Date')
# plt.ylabel('Ventes')
# plt.show()
# 2. Rendre la série stationnaire (détermination de d)
# On peut observer une tendance et une saisonnalité, donc différenciation nécessaire.
# Ici, on suppose d=1 après analyse ACF/PACF ou test ADF.
sales_diff = sales_data.diff().dropna()
# Visualisation de la série différenciée (pour analyse ACF/PACF)
# plt.figure(figsize=(12, 6))
# plt.plot(sales_diff)
# plt.title('Série Temporelle Différenciée')
# plt.show()
# Plot ACF et PACF pour déterminer p et q
# plot_acf(sales_diff, lags=20)
# plt.title('Autocorrélation (ACF)')
# plt.show()
# plot_pacf(sales_diff, lags=20)
# plt.title('Autocorrélation Partielle (PACF)')
# plt.show()
# Après analyse ACF/PACF (par exemple, p=2, q=2)
# Nous allons utiliser un ordre (2,1,2) pour l'exemple.
order = (2, 1, 2)
# 3. Séparation des données en entraînement et test
train_size = int(len(sales_data) * 0.8)
train_data, test_data = sales_data[:train_size], sales_data[train_size:]
# 4. Estimation du modèle ARIMA
# L'objet ARIMA prend en charge la différenciation interne si d > 0
model = ARIMA(train_data, order=order)
model_fit = model.fit()
print("Résumé du modèle ARIMA:")
print(model_fit.summary())
# 5. Prévisions pour les 15 prochains mois (par exemple, pour 2026)
forecast_steps = len(test_data) + 15 # Prévoir la période de test + 15 mois pour 2026
forecast_start_index = len(sales_data) - len(test_data)
forecast_end_index = forecast_start_index + forecast_steps -1
# Obtenir les indices de prévision corrects
forecast_index = pd.date_range(start=test_data.index[0], periods=forecast_steps, freq='MS')
forecast_result = model_fit.predict(start=forecast_index[0], end=forecast_index[-1])
# Reconstruire les prévisions sur la série originale (si différenciation a été appliquée)
# Pour ARIMA de statsmodels, .predict() retourne les valeurs prédites directement,
# pas les valeurs différenciées, donc pas besoin de réintégration manuelle si d > 0.
# Visualisation des résultats
plt.figure(figsize=(14, 7))
plt.plot(train_data.index, train_data, label='Données d\'entraînement')
plt.plot(test_data.index, test_data, label='Données réelles (test)', color='orange')
plt.plot(forecast_index, forecast_result, label=f'Prévisions ARIMA({order[0]},{order[1]},{order[2]})', color='green', linestyle='--')
plt.title(f'Prévisions de Ventes avec ARIMA({order[0]},{order[1]},{order[2]}) pour 2026')
plt.xlabel('Date')
plt.ylabel('Ventes')
plt.legend()
plt.grid(True)
plt.show()
Ce code est un exemple simplifié. Dans une application réelle, la détermination des paramètres p, d, q implique une analyse plus approfondie des graphiques ACF/PACF et des tests statistiques pour la stationnarité. Il existe également des approches automatiques comme pmdarima qui peuvent rechercher les meilleurs paramètres ARIMA pour vous.
POINT CLÉ
ARIMA (p, d, q) est un modèle puissant mais exigeant en matière de préparation des données (stationnarité) et de sélection des paramètres. L’analyse des fonctions ACF et PACF est cruciale pour identifier les ordres p et q.
MODÉLISATION PROPHET
4. Prophet : La Simplicité de Facebook pour des Prévisions Robustes
Développé par Facebook, Prophet est une bibliothèque de prévision de séries temporelles conçue pour être intuitive et robuste, même pour les séries temporelles qui présentent de fortes saisonnalités et des effets de jours fériés. Contrairement à ARIMA, qui est un modèle plus statistique et « boîte noire », Prophet est plus axé sur l’ingénierie des caractéristiques et la décomposition de la série.
Le Modèle Additif de Prophet
Prophet utilise un modèle additif généralisé, où la prévision y(t) est la somme de trois composantes principales :
y(t) = g(t) + s(t) + h(t) + ε(t)
g(t)(Tendance) : Modélise la tendance non linéaire de la série temporelle. Prophet utilise un modèle de croissance logistique ou linéaire par morceaux pour s’adapter aux changements de tendance.s(t)(Saisonnalité) : Représente les effets saisonniers périodiques (hebdomadaires, annuels). Prophet utilise des séries de Fourier pour modéliser la saisonnalité, ce qui lui permet de capturer des motifs complexes.h(t)(Jours Fériés et Événements) : Permet d’inclure des effets d’événements spécifiques ou de jours fériés, qui peuvent avoir un impact significatif sur la série temporelle.ε(t)(Terme d’erreur) : Représente le bruit aléatoire qui n’est pas expliqué par le modèle.
Avantages de Prophet
- Facilité d’utilisation : Nécessite peu de configuration manuelle des paramètres. Il suffit d’un DataFrame avec deux colonnes :
ds(datestamp) ety(valeur). - Gestion de la saisonnalité : Gère automatiquement la saisonnalité annuelle, hebdomadaire et quotidienne. Il est facile d’ajouter des saisonnalités personnalisées.
- Jours fériés et événements : Permet d’intégrer facilement des listes de jours fériés ou d’événements spéciaux, améliorant la précision des prévisions.
- Robuste aux données manquantes et aberrantes : Fonctionne bien même avec des lacunes dans les données ou des valeurs extrêmes.
- Interprétabilité : Les différentes composantes du modèle (tendance, saisonnalité, jours fériés) peuvent être visualisées et comprises séparément.
Exemple Pratique avec Prophet en Python
Reprenons nos données de ventes simulées et appliquons Prophet. Vous verrez à quel point l’implémentation est simple.
EXPLICATION DU CODE
Ce script prépare les données pour Prophet en les formatant avec les colonnes ds et y. Il initialise ensuite le modèle Prophet, l’entraîne, puis génère des prévisions pour les 15 prochains mois, incluant la visualisation des composants.
import pandas as pd
import numpy as np
from prophet import Prophet
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
# 1. Génération ou réutilisation des données simulées
np.random.seed(42)
dates = pd.date_range(start='2020-01-01', periods=72, freq='MS') # 6 ans de données
data = 100 + np.arange(72) * 2 + np.sin(np.arange(72) * 2 * np.pi / 12) * 50 + np.random.normal(0, 10, 72)
sales_data = pd.Series(data, index=dates)
# 2. Préparation des données pour Prophet (format 'ds', 'y')
df_prophet = sales_data.reset_index()
df_prophet.columns = ['ds', 'y']
# 3. Séparation des données en entraînement et test
train_size = int(len(df_prophet) * 0.8)
train_df, test_df = df_prophet[:train_size], df_prophet[train_size:]
# 4. Initialisation et entraînement du modèle Prophet
model_prophet = Prophet(
seasonality_mode='additive', # ou 'multiplicative' si l'amplitude saisonnière varie avec la tendance
yearly_seasonality=True,
weekly_seasonality=False, # Données mensuelles, pas de saisonnalité hebdomadaire
daily_seasonality=False
)
model_prophet.fit(train_df)
# 5. Création d'un DataFrame pour les prévisions futures
future = model_prophet.make_future_dataframe(periods=len(test_df) + 15, freq='MS') # Prévoir la période de test + 15 mois pour 2026
# 6. Génération des prévisions
forecast = model_prophet.predict(future)
# 7. Visualisation des prévisions
plt.figure(figsize=(14, 7))
model_prophet.plot(forecast, ax=plt.gca())
plt.plot(train_df['ds'], train_df['y'], 'o', markersize=4, label='Données d\'entraînement', color='blue')
plt.plot(test_df['ds'], test_df['y'], 'o', markersize=4, label='Données réelles (test)', color='orange')
plt.title('Prévisions de Ventes avec Prophet pour 2026')
plt.xlabel('Date')
plt.ylabel('Ventes')
plt.legend()
plt.grid(True)
plt.show()
# 8. Visualisation des composants du modèle
fig2 = model_prophet.plot_components(forecast)
plt.show()
Prophet fournit des graphiques très utiles pour visualiser la tendance, la saisonnalité annuelle, hebdomadaire et quotidienne (si activées). Cela offre une grande interprétabilité du modèle, ce qui est un atout majeur pour la communication des résultats.
POINT CLÉ
Prophet excelle par sa simplicité d’utilisation et sa robustesse face aux données complexes, aux données manquantes et aux jours fériés. Son approche par décomposition du modèle additif facilite l’interprétation des tendances et saisonnalités.
COMPARAISON
5. Analyse Comparative : ARIMA vs. Prophet
Maintenant que nous avons exploré ARIMA et Prophet individuellement, il est essentiel de comprendre quand utiliser l’un ou l’autre. Le choix dépendra de la nature de vos données, de vos compétences techniques, et des exigences de votre projet.
Tableau Comparatif : ARIMA vs. Prophet
| Caractéristique | ARIMA | Prophet (Facebook) |
|---|---|---|
| Philosophie | Modèle statistique classique basé sur la corrélation passée des données. | Modèle additif de décomposition, conçu pour les prévisions à l’échelle. |
| Exigences de données | Nécessite une série temporelle stationnaire (moyenne, variance constantes). | Moins exigeant, gère bien les données non stationnaires, manquantes, et les outliers. |
| Saisonnalité | Géré par des extensions SARIMA ou SARIMAX, plus complexe à configurer. | Gère automatiquement la saisonnalité (quotidienne, hebdomadaire, annuelle) et les jours fériés. |
| Interprétabilité | Moins directe, nécessite une compréhension statistique des coefficients. | Très bonne, visualisation claire des composants (tendance, saisonnalité, jours fériés). |
| Ajustement des paramètres | Nécessite une analyse manuelle (ACF/PACF) ou des boucles de recherche (auto_arima). | Peu de paramètres à ajuster manuellement, souvent les valeurs par défaut suffisent. |
| Rapidité | Rapide pour des séries courtes sans recherche de paramètres. | Généralement rapide, même avec des jeux de données volumineux. |
| Cas d’utilisation | Données plus stables, sans saisonnalité complexe ou jours fériés importants. Quand la stationnarité est atteignable. | Idéal pour les séries temporelles avec une forte saisonnalité, des jours fériés, des changements de tendance (ex: données d’affaires, marketing). |
Quand Choisir Quel Modèle ?
Choisissez ARIMA (ou SARIMA pour la saisonnalité) si :
- Vous avez une bonne compréhension des concepts statistiques des séries temporelles (stationnarité, ACF/PACF).
- Vos données sont relativement « propres » et ne présentent pas de lacunes importantes ou de valeurs aberrantes extrêmes.
- La saisonnalité est simple ou absente, ou vous êtes prêt à explorer SARIMA pour la modéliser explicitement.
- Vous préférez une approche plus « traditionnelle » et moins dépendante d’hypothèses heuristiques.
Choisissez Prophet si :
- Vous travaillez avec des données d’affaires ou de performance qui ont souvent des saisonnalités complexes (quotidienne, hebdomadaire, annuelle) et des jours fériés.
- Vous avez besoin d’un outil robuste qui gère bien les données manquantes, les outliers et les changements de tendance.
- La facilité d’utilisation et l’interprétabilité du modèle sont des priorités.
- Vous devez générer rapidement des prévisions fiables pour de nombreuses séries temporelles sans passer trop de temps sur l’ajustement des paramètres.
POINT CLÉ
ARIMA est un modèle statistique puissant pour les séries stationnaires, nécessitant une expertise. Prophet est plus flexible et user-friendly, idéal pour les données avec forte saisonnalité et jours fériés, souvent rencontrées dans le monde des affaires.
DÉFIS & SOLUTIONS
6. Défis et Solutions Courantes en Prévision
La prévision de séries temporelles n’est pas toujours un chemin linéaire. Des défis courants peuvent survenir, mais des solutions existent pour les surmonter et garantir des modèles robustes et fiables.
PROBLÈME 01
Données Manquantes et Valeurs Aberrantes
Les séries temporelles réelles sont rarement parfaites. Des capteurs peuvent tomber en panne, des enregistrements peuvent être corrompus, ou des événements imprévus peuvent créer des valeurs extrêmes (outliers). Ces imperfections peuvent grandement affecter la performance des modèles de prévision.
SOLUTION — Imputation et Détection Robuste
Pour les données manquantes, l’imputation est essentielle. Des méthodes simples incluent la moyenne mobile, l’interpolation linéaire ou polynomiale. Pour les valeurs aberrantes, Prophet est intrinsèquement plus robuste, mais pour ARIMA, il est souvent nécessaire de les identifier et de les traiter (par exemple, les remplacer par la médiane ou une valeur imputée).
EXPLICATION DU CODE
Ce code illustre la gestion des données manquantes par interpolation linéaire et la détection d’outliers simples à l’aide de l’écart interquartile (IQR).
import pandas as pd
import numpy as np
# Données simulées avec des valeurs manquantes et un outlier
np.random.seed(42)
dates = pd.date_range(start='2023-01-01', periods=24, freq='MS')
data = 100 + np.arange(24) * 5 + np.random.normal(0, 10, 24)
ts_corrupted = pd.Series(data, index=dates)
# Introduire des NaN
ts_corrupted.iloc[5] = np.nan
ts_corrupted.iloc[12] = np.nan
# Introduire un outlier
ts_corrupted.iloc[18] = 500 # Valeur aberrante
print("Série temporelle corrompue:\n", ts_corrupted)
# 1. Traitement des valeurs manquantes par interpolation linéaire
ts_imputed = ts_corrupted.interpolate(method='linear')
print("\nSérie temporelle après imputation:\n", ts_imputed)
# 2. Détection et traitement des outliers (méthode IQR)
Q1 = ts_imputed.quantile(0.25)
Q3 = ts_imputed.quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
outliers = ts_imputed[(ts_imputed < lower_bound) | (ts_imputed > upper_bound)]
print("\nOutliers détectés:\n", outliers)
# Traitement des outliers (ex: remplacement par la médiane ou la limite la plus proche)
ts_cleaned = ts_imputed.copy()
ts_cleaned[ts_cleaned < lower_bound] = lower_bound
ts_cleaned[ts_cleaned > upper_bound] = upper_bound
print("\nSérie temporelle après traitement des outliers:\n", ts_cleaned)
PROBLÈME 02
Surapprentissage et Sous-apprentissage
Le surapprentissage (overfitting) se produit lorsque le modèle apprend trop bien les particularités du bruit dans les données d’entraînement, ce qui le rend incapable de généraliser à de nouvelles données. Le sous-apprentissage (underfitting) se produit lorsque le modèle est trop simple pour capturer les motifs sous-jacents des données.
SOLUTION — Validation Croisée et Réglage des Hyperparamètres
La validation croisée sur séries temporelles est cruciale pour évaluer la performance du modèle sur des données non vues. Des techniques comme la validation croisée glissante (rolling forecast origin) sont préférables. Le réglage des hyperparamètres (comme les ordres p, d, q pour ARIMA ou les paramètres de saisonnalité/changepoints pour Prophet) permet d’optimiser l’équilibre entre la complexité du modèle et sa capacité de généralisation.
POINT CLÉ
Une bonne préparation des données (imputation, traitement des outliers) et une évaluation rigoureuse via la validation croisée sont essentielles pour construire des modèles de prévision fiables et éviter le sur/sous-apprentissage.
OPTIMISATION
7. Application Pratique Avancée : Optimisation et Évaluation
La simple construction d’un modèle ne suffit pas ; il faut aussi l’optimiser et évaluer sa performance de manière rigoureuse pour s’assurer qu’il fournit des prévisions précises et utiles.
Réglage des Hyperparamètres
Le réglage des hyperparamètres est le processus de recherche des meilleurs paramètres pour votre modèle. Pour ARIMA, cela implique de trouver les ordres p, d, q (et P, D, Q, S pour SARIMA). Pour Prophet, il s’agit d’ajuster la flexibilité de la tendance (changepoint_prior_scale), la force de la saisonnalité (seasonality_prior_scale) ou d’ajouter des régresseurs externes.
Des techniques comme la recherche en grille (GridSearchCV) ou la recherche aléatoire (RandomizedSearchCV), bien que plus coûteuses en calcul, peuvent être adaptées aux séries temporelles pour trouver les combinaisons optimales.
Métriques d’Évaluation des Prévisions
Pour quantifier la précision de vos prévisions, plusieurs métriques sont couramment utilisées :
- MAE (Mean Absolute Error) : Moyenne des valeurs absolues des erreurs. Facile à interpréter, en unités de la série originale.
- RMSE (Root Mean Squared Error) : Racine carrée de la moyenne des erreurs au carré. Pénalise davantage les grandes erreurs. Également en unités de la série.
- MAPE (Mean Absolute Percentage Error) : Moyenne des erreurs absolues en pourcentage. Utile pour comparer des modèles sur différentes échelles, mais sensible aux valeurs proches de zéro.
- R-squared (R²) : Mesure la proportion de la variance de la variable dépendante qui est prévisible à partir de la variable indépendante.
Exemple de Validation Croisée et Évaluation avec Prophet
Prophet propose des outils intégrés pour la validation croisée, ce qui simplifie grandement le processus.
EXPLICATION DU CODE
Ce code utilise les fonctions de validation croisée de Prophet (cross_validation et performance_metrics) pour évaluer le modèle sur différentes périodes de prévision. Les métriques comme le MAPE, le RMSE et le MAE sont calculées et affichées, offrant une vue d’ensemble de la performance du modèle.
import pandas as pd
import numpy as np
from prophet import Prophet
from prophet.diagnostics import cross_validation, performance_metrics
from prophet.plot import plot_cross_validation_metric
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
# 1. Réutilisation des données Prophet préparées
np.random.seed(42)
dates = pd.date_range(start='2020-01-01', periods=72, freq='MS') # 6 ans de données
data = 100 + np.arange(72) * 2 + np.sin(np.arange(72) * 2 * np.pi / 12) * 50 + np.random.normal(0, 10, 72)
sales_data = pd.Series(data, index=dates)
df_prophet = sales_data.reset_index()
df_prophet.columns = ['ds', 'y']
# 2. Initialisation et entraînement du modèle Prophet
model_prophet_cv = Prophet(
seasonality_mode='additive',
yearly_seasonality=True,
weekly_seasonality=False,
daily_seasonality=False
)
model_prophet_cv.fit(df_prophet) # Entraînement sur toutes les données pour la CV
# 3. Exécution de la validation croisée
# initial: période d'entraînement initiale (ici, 3 ans)
# period: fréquence de coupe (ici, tous les 6 mois)
# horizon: période de prévision (ici, 1 an)
df_cv = cross_validation(
model_prophet_cv, initial='1095 days', period='180 days', horizon='365 days'
)
print("Résultats de la validation croisée (premières lignes):\n", df_cv.head())
# 4. Calcul des métriques de performance
df_p = performance_metrics(df_cv)
print("\nMétriques de performance (premières lignes):\n", df_p.head())
# 5. Visualisation d'une métrique de performance (ex: MAPE)
fig = plot_cross_validation_metric(df_cv, metric='mape')
plt.title('MAPE de la Validation Croisée pour Prophet')
plt.xlabel('Horizon de Prévision')
plt.ylabel('MAPE')
plt.show()
# Afficher les métriques clés pour un horizon spécifique (ex: 365 jours)
print("\nMétrique MAPE moyenne pour un horizon de 365 jours:", df_p['mape'].mean())
print("Métrique RMSE moyenne pour un horizon de 365 jours:", df_p['rmse'].mean())
print("Métrique MAE moyenne pour un horizon de 365 jours:", df_p['mae'].mean())
Catégories Développement, IA & ML