
RÉSUMÉ
[DevOps & Cloud] Démarrer avec Kubernetes en 2026 : Guide complet pour développeurs
Un guide pratique pour les développeurs souhaitant maîtriser les bases de Kubernetes (K8s) et déployer leurs applications conteneurisées efficacement.
Keywords: Kubernetes, K8s, Orchestration Conteneurs
TABLE DES MATIÈRES
1. Contexte : L’indispensable Kubernetes en 2026
2. Comprendre Kubernetes : Architecture et Concepts Clés
3. Les Fondamentaux de Kubernetes pour Développeurs
4. Résolution de Problèmes Communs et Bonnes Pratiques
5. Application Pratique : Déploiement d’une Application Web Multi-Services
6. L’Écosystème Kubernetes en 2026 : Outils Essentiels
7. Perspectives d’Évolution et Tendances Futures
8. Questions Fréquentes (FAQ)
CONTEXTE
L’indispensable Kubernetes en 2026
En 2026, l’écosystème du développement logiciel est plus que jamais centré sur l’agilité, la scalabilité et la résilience. Au cœur de cette transformation se trouve la conteneurisation, et son chef d’orchestre incontesté : Kubernetes (souvent abrégé en K8s). Pour tout développeur soucieux de moderniser ses pratiques et de déployer des applications robustes dans le cloud, la maîtrise de Kubernetes n’est plus une option, mais une nécessité.
L’adoption des microservices et des architectures distribuées a explosé au cours des dernières années. Selon une étude récente de la Cloud Native Computing Foundation (CNCF) datant de fin 2025, près de 90% des entreprises interrogées utilisent des conteneurs en production, et parmi elles, plus de 75% ont choisi Kubernetes comme plateforme d’orchestration. Ces chiffres soulignent non seulement la maturité de K8s, mais aussi son rôle central dans les stratégies DevOps et Cloud de la plupart des organisations, des startups innovantes aux géants de l’industrie.
Ce guide est conçu pour vous, développeurs, afin de démystifier Kubernetes et de vous fournir les bases solides nécessaires pour commencer à déployer et gérer vos applications conteneurisées. Nous allons décrypter le jargon technique, explorer les concepts fondamentaux et vous guider à travers des exemples concrets pour que vous puissiez rapidement mettre en pratique vos nouvelles connaissances. Que vous soyez débutant avec Kubernetes ou que vous cherchiez à rafraîchir vos compétences, ce rapport d’analyse vous accompagnera pas à pas dans l’univers de l’orchestration de conteneurs.
POINT CLÉ
En 2026, Kubernetes est devenu la norme de facto pour l’orchestration de conteneurs, essentiel pour la scalabilité, la résilience et l’automatisation des déploiements d’applications modernes. Ignorer K8s, c’est se priver d’un avantage concurrentiel majeur.
ANALYSE DÉTAILLÉE
Comprendre Kubernetes : Architecture et Concepts Clés
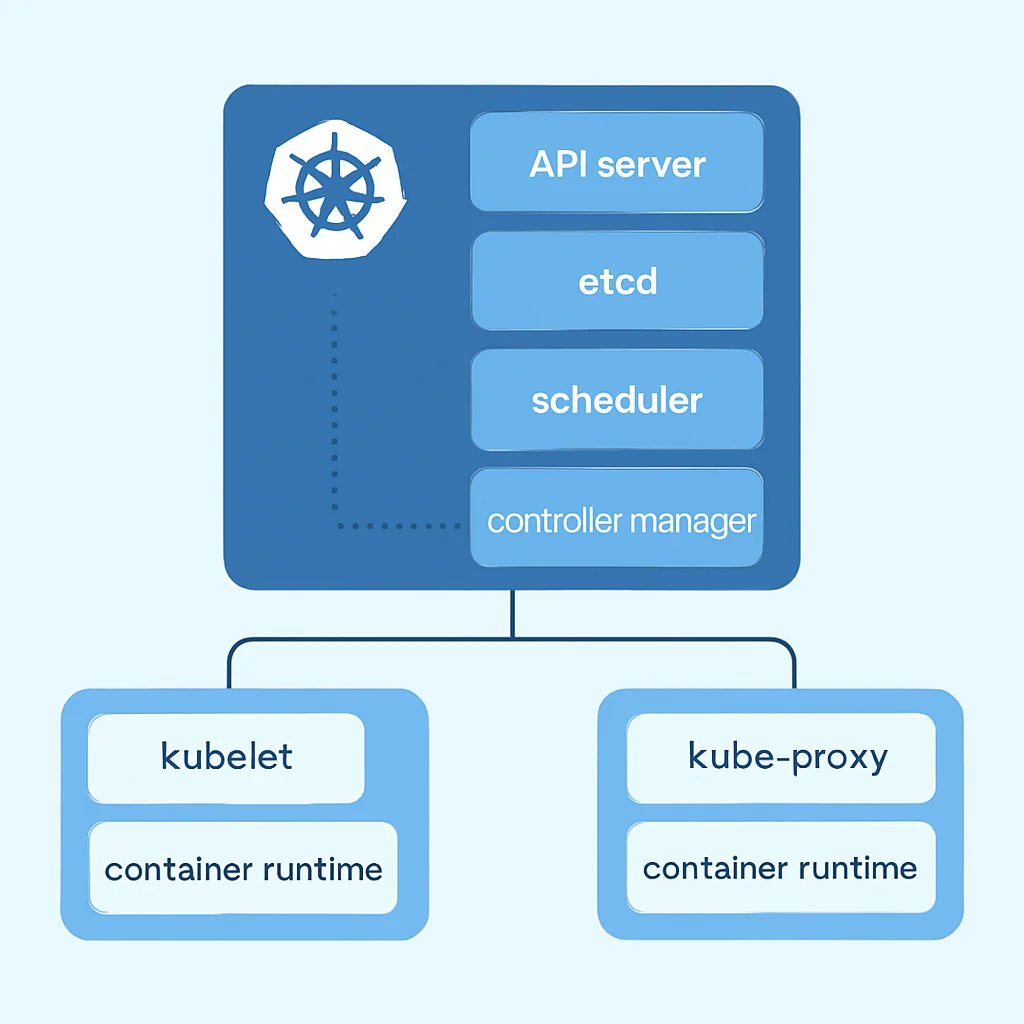
Avant de plonger dans le code, il est crucial de comprendre la structure et les composants fondamentaux de Kubernetes. Un cluster Kubernetes est un ensemble de machines (physiques ou virtuelles) qui travaillent ensemble pour exécuter vos applications conteneurisées. Il se compose principalement de deux types de nœuds : le plan de contrôle (Control Plane) et les nœuds de travail (Worker Nodes).
Le Plan de Contrôle (Control Plane)
Le plan de contrôle est le cerveau du cluster. Il gère l’état global du cluster, prend les décisions d’ordonnancement et réagit aux événements. Ses composants principaux incluent :
- Kube-apiserver : Le point d’entrée principal pour toutes les communications avec le cluster. C’est l’API REST que vous utilisez via
kubectl. - etcd : Une base de données clé-valeur distribuée, cohérente et hautement disponible qui stocke l’état complet du cluster Kubernetes.
- Kube-scheduler : Responsable de l’affectation des Pods aux nœuds de travail disponibles, en tenant compte des ressources requises et des contraintes.
- Kube-controller-manager : Exécute divers contrôleurs qui régulent l’état du cluster (ex: contrôleur de réplication, contrôleur de déploiement).
- Cloud-controller-manager (si utilisé dans un cloud public) : Interagit avec l’API du fournisseur de cloud pour gérer les ressources spécifiques au cloud (ex: load balancers, volumes persistants).
Les Nœuds de Travail (Worker Nodes)
Les nœuds de travail sont les machines où vos applications (conteneurs) s’exécutent réellement. Chaque nœud de travail comprend :
- Kubelet : Un agent qui s’exécute sur chaque nœud et assure que les conteneurs décrits dans les Pods sont en cours d’exécution et en bonne santé.
- Kube-proxy : Maintient les règles réseau sur les nœuds, permettant la communication réseau vers vos Pods, à la fois depuis l’intérieur et l’extérieur du cluster.
- Container Runtime : Le logiciel qui est responsable de l’exécution des conteneurs (ex: Docker, containerd, CRI-O).
Cette architecture distribuée permet à Kubernetes d’offrir une haute disponibilité et une tolérance aux pannes. Si un nœud de travail tombe en panne, le plan de contrôle peut redémarrer les Pods affectés sur d’autres nœuds sains. De même, si un composant du plan de contrôle échoue, les architectures modernes de Kubernetes (comme les clusters gérés des fournisseurs de cloud) garantissent sa résilience.
POINT CLÉ
Comprendre l’architecture Master/Worker de Kubernetes est fondamental. Le Control Plane gère l’état global et prend les décisions, tandis que les Worker Nodes exécutent les charges de travail conteneurisées via Kubelet et Kube-proxy.
CONTENU PRINCIPAL
Les Fondamentaux de Kubernetes pour Développeurs
En tant que développeur, vous interagirez principalement avec les ressources de Kubernetes via des fichiers YAML déclaratifs. Ces fichiers décrivent l’état souhaité de votre application. Voici les concepts clés que vous rencontrerez le plus souvent :
Pods : L’Unité de Déploiement Minimale
Un Pod est la plus petite unité déployable dans Kubernetes. Il encapsule un ou plusieurs conteneurs (qui partagent le même réseau et le même stockage), ainsi que les ressources de stockage et les options de configuration. Il est important de noter que les Pods sont éphémères : ils peuvent être créés, détruits et redémarrés. Vous ne créez généralement pas de Pods directement, mais via des ressources de niveau supérieur comme les Deployments.
Deployments : Gérer les Pods et les Mises à Jour
Un Deployment est une ressource qui gère un ensemble de Pods répliqués. Il permet de :
- Définir le nombre de réplicas (instances) de votre application.
- Gérer les mises à jour progressives (rolling updates) et les retours arrière (rollbacks) sans interruption de service.
- Assurer l’auto-réparation : si un Pod tombe en panne, le Deployment en crée un nouveau.
Services : Exposer vos Applications
Les Pods ont des adresses IP qui changent à chaque redémarrage. Pour garantir que votre application reste accessible de manière stable, vous utilisez un Service. Un Service fournit une adresse IP stable et un nom DNS pour un ensemble de Pods, agissant comme un load balancer. Les types de Services courants sont :
- ClusterIP : Expose le Service sur une IP interne au cluster. Accessible uniquement depuis l’intérieur du cluster.
- NodePort : Expose le Service sur un port statique sur chaque nœud du cluster. Accessible de l’extérieur via
<NodeIP>:<NodePort>. - LoadBalancer : Expose le Service via un load balancer externe du fournisseur de cloud. Nécessite un fournisseur de cloud.
Namespaces : Isolation Logique
Les Namespaces sont un moyen de diviser un cluster Kubernetes en plusieurs environnements virtuels. Cela permet d’isoler les ressources (Pods, Deployments, Services, etc.) entre différentes équipes ou applications, évitant les conflits de noms et améliorant la gestion. Par exemple, vous pourriez avoir un namespace dev, staging et prod au sein du même cluster.
Exemple Concret : Déploiement d’une Application Nginx Simple
Voyons comment déployer une application Nginx de base avec un Deployment et un Service.
EXPLICATION DU CODE
Ce fichier YAML définit un Deployment pour Nginx avec 3 réplicas et un Service de type NodePort pour le rendre accessible depuis l’extérieur du cluster. Le sélecteur app: nginx lie le Service au Deployment.
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: nginx-service
spec:
selector:
app: nginx
type: NodePort
ports:
- protocol: TCP
port: 80
targetPort: 80
nodePort: 30080 # Un port entre 30000-32767
Pour déployer ceci, enregistrez le code ci-dessus dans un fichier nginx-app.yaml et exécutez :
kubectl apply -f nginx-app.yamlPour vérifier le statut et obtenir l’URL de votre application :
kubectl get deployment nginx-deployment
kubectl get service nginx-serviceVous devriez voir que le Deployment a créé 3 Pods et que le Service est accessible via l’adresse IP de votre nœud de cluster et le port 30080.
POINT CLÉ
La configuration déclarative via des fichiers YAML est au cœur de Kubernetes. Elle permet de décrire l’état souhaité de votre infrastructure et de vos applications, laissant Kubernetes s’occuper de l’atteindre et de le maintenir.
RÉSOLUTION DE PROBLÈMES
Résolution de Problèmes Communs et Bonnes Pratiques
L’orchestration de conteneurs introduit de nouvelles problématiques, notamment en matière de gestion des données sensibles et de persistance. Kubernetes offre des solutions robustes pour ces défis.
Problème 01 : Gestion Sécurisée des Informations Sensibles (Secrets)
Les applications nécessitent souvent des informations sensibles comme des mots de passe de base de données, des clés API ou des jetons. Les stocker directement dans les images Docker ou les fichiers de configuration est une mauvaise pratique de sécurité.
PROBLÈME 01
Exposer des informations sensibles dans le code ou les configurations brutes.
Le stockage en clair de mots de passe, clés API ou autres données confidentielles dans des fichiers de configuration ou des images de conteneurs représente une faille de sécurité majeure, augmentant les risques d’accès non autorisé et de compromission du système.
SOLUTION — Utiliser les Secrets Kubernetes pour gérer les données sensibles.
Kubernetes offre une ressource appelée Secret pour stocker et gérer les informations sensibles. Les Secrets peuvent être montés comme des fichiers dans les Pods ou injectés comme variables d’environnement. Bien que les Secrets ne soient pas chiffrés par défaut dans etcd, ils offrent une bien meilleure isolation que les variables d’environnement directes ou les fichiers de configuration dans l’image. Pour un chiffrement au repos, des solutions externes comme Vault ou des fournisseurs de KMS cloud sont recommandées.
EXPLICATION DU CODE
Ce code crée un Secret nommé my-secret avec des données encodées en Base64. Ensuite, il montre comment un Pod peut utiliser ce secret en le montant comme un volume, rendant les données accessibles sous forme de fichiers dans le conteneur.
apiVersion: v1
kind: Secret
metadata:
name: my-secret
type: Opaque
data:
username: dXNlcg== # "user" encodé en Base64
password: cGFzcw== # "pass" encodé en Base64
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: app-with-secret
spec:
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- name: mycontainer
image: busybox
command: ["sh", "-c", "echo $(cat /etc/secret/username) && echo $(cat /etc/secret/password) && sleep 3600"]
volumeMounts:
- name: secret-volume
mountPath: "/etc/secret"
readOnly: true
volumes:
- name: secret-volume
secret:
secretName: my-secret
Problème 02 : Gérer la Persistance des Données
Les Pods sont éphémères. Si un Pod est détruit et recréé, toutes les données stockées localement à l’intérieur du conteneur sont perdues. Les applications avec état (bases de données, caches) nécessitent un stockage persistant.
PROBLÈME 02
Perte de données critiques lorsque les Pods sont redémarrés ou déplacés.
L’éphémérité des Pods de Kubernetes signifie que toute donnée non persistante stockée à l’intérieur d’un conteneur sera perdue lors de sa destruction, ce qui est inacceptable pour les applications nécessitant un état durable, comme les bases de données ou les systèmes de fichiers partagés.
SOLUTION — Utiliser les Persistent Volumes (PV) et Persistent Volume Claims (PVC).
Kubernetes sépare le stockage physique (Persistent Volume – PV) de la demande de stockage (Persistent Volume Claim – PVC). Un PV est une ressource de stockage dans le cluster (ex: volume AWS EBS, Azure Disk, Google Persistent Disk, NFS). Un PVC est une demande de stockage par un utilisateur. Lorsque vous créez un PVC, Kubernetes tente de trouver un PV correspondant (ou d’en provisionner un dynamiquement) et de le lier au PVC, qui peut ensuite être monté dans un Pod.
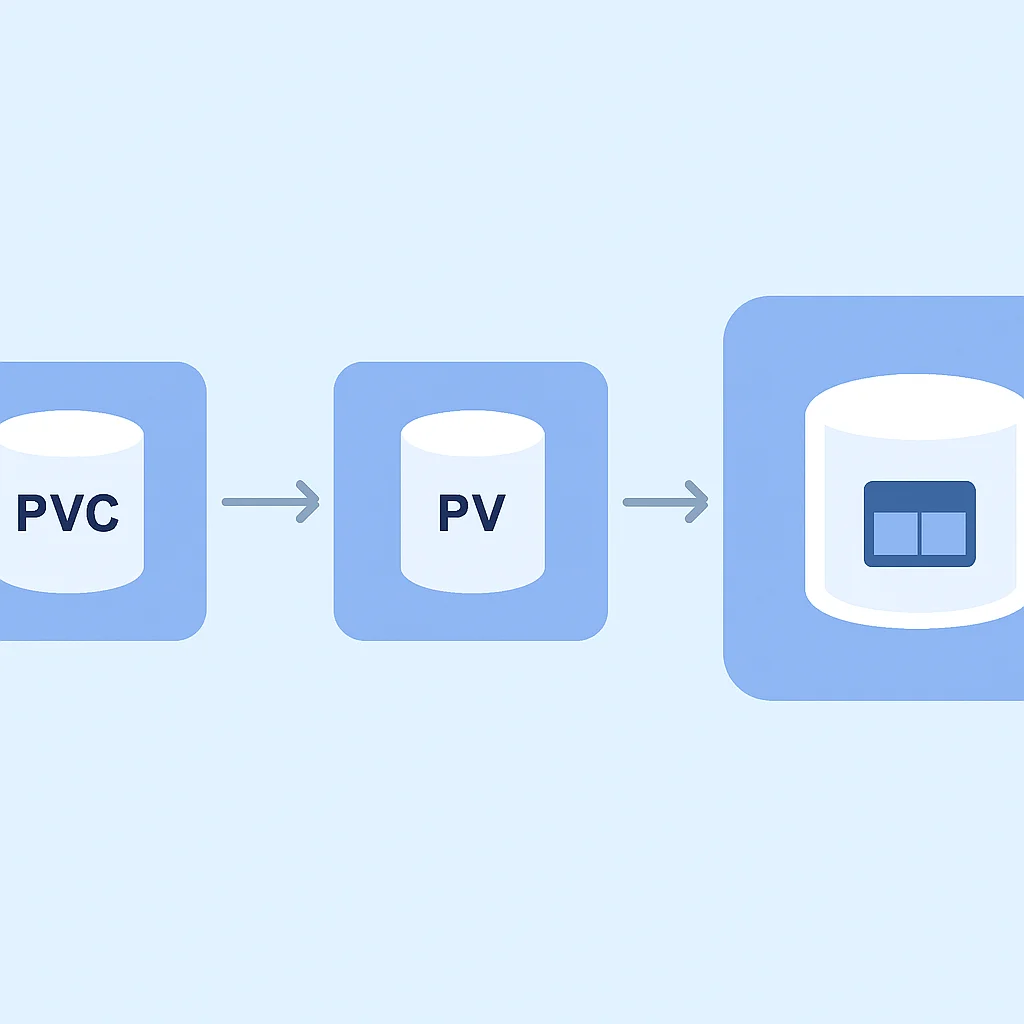
EXPLICATION DU CODE
Ce code définit un Persistent Volume Claim (PVC) demandant 1 GiB de stockage. Ensuite, un Deployment utilise ce PVC pour monter un volume persistant dans le Pod, assurant que les données écrites dans /data persistent même si le Pod est recréé.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: my-pvc
spec:
accessModes:
- ReadWriteOnce # Le volume peut être monté en lecture-écriture par un seul nœud
resources:
requests:
storage: 1Gi # Demande 1 Gigaoctet de stockage
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: app-with-pv
spec:
selector:
matchLabels:
app: myapp-data
template:
metadata:
labels:
app: myapp-data
spec:
containers:
- name: mycontainer-data
image: busybox
command: ["sh", "-c", "echo 'Hello from persistent storage' > /data/hello.txt && sleep 3600"]
volumeMounts:
- name: persistent-storage
mountPath: "/data"
volumes:
- name: persistent-storage
persistentVolumeClaim:
claimName: my-pvc
POINT CLÉ
Les Secrets et les Persistent Volumes/Claims sont essentiels pour la sécurité et la persistance des données dans Kubernetes. Adoptez-les dès le début de vos projets pour bâtir des applications robustes et sécurisées.
APPLICATION PRATIQUE
Application Pratique : Déploiement d’une Application Web Multi-Services
Pour illustrer la puissance de Kubernetes, nous allons esquisser le déploiement d’une application web simple composée d’un frontend (React/Nginx) et d’un backend (Node.js API) qui interagit avec une base de données MongoDB. Bien que le déploiement complet de MongoDB sur Kubernetes soit complexe (souvent on utilise des services managés), nous nous concentrerons sur le frontend et le backend.
Prérequis : Conteneurisation des Services
Chaque composant de votre application doit être conteneurisé. Supposons que vous ayez déjà des images Docker pour votre frontend (par exemple, monapp/frontend:1.0) et votre backend (par exemple, monapp/backend:1.0), poussées vers un registre d’images (Docker Hub, Google Container Registry, etc.).
Étapes de Déploiement sur Kubernetes
1
Définir le Backend (Deployment & Service)
Créez un fichier YAML pour le déploiement de votre API backend. Ce déploiement gérera les Pods de votre backend. Un Service de type ClusterIP sera utilisé pour permettre au frontend de communiquer avec le backend en interne.
2
Définir le Frontend (Deployment & Service)
Créez un fichier YAML pour le déploiement de votre application frontend. Pour exposer le frontend au monde extérieur, nous utiliserons un Service de type LoadBalancer (ou NodePort si vous n’êtes pas sur un cloud public, ou Ingress pour des scénarios plus avancés).
3
Appliquer les Configurations
Une fois vos fichiers YAML prêts (par exemple backend.yaml et frontend.yaml), utilisez kubectl apply -f <fichier> pour les déployer.
4
Vérifier et Accéder
Utilisez kubectl get deployments, kubectl get pods et kubectl get services pour vérifier l’état de vos ressources. L’adresse IP externe de votre frontend sera visible dans la sortie de kubectl get services pour le Service de type LoadBalancer.
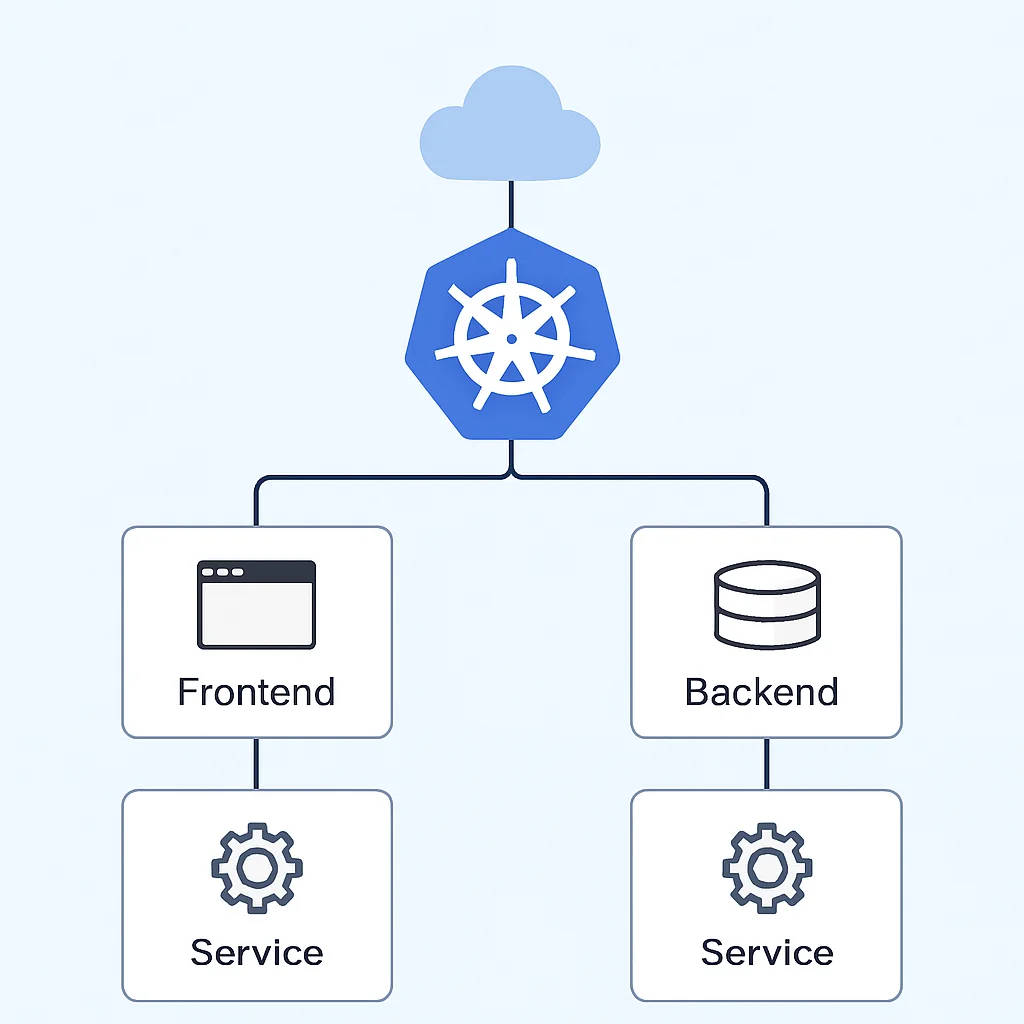
Ce processus met en évidence la modularité et la gestion déclarative offertes par Kubernetes. Chaque composant de l’application est géré indépendamment, ce qui facilite les mises à jour et la scalabilité. Par exemple, si votre backend nécessite plus de ressources, vous pouvez simplement augmenter le nombre de réplicas de son Deployment sans affecter le frontend.
POINT CLÉ
Le déploiement d’applications multi-services sur Kubernetes est facilité par la décomposition en ressources indépendantes (Deployments, Services). Cela permet une gestion granulaire, une scalabilité aisée et des mises à jour sans interruption.
ÉCOSYSTÈME
L’Écosystème Kubernetes en 2026 : Outils Essentiels
Kubernetes n’est pas seulement un orchestrateur ; c’est un écosystème vaste et dynamique. Plusieurs outils gravitent autour de K8s pour améliorer l’expérience des développeurs et des opérateurs.
kubectl : Le Compagnon Indispensable
L’outil en ligne de commande kubectl est votre interface principale avec le cluster Kubernetes. Il permet d’exécuter des commandes sur le cluster, de déployer des applications, d’inspecter l’état des ressources, de déboguer, etc. Sa polyvalence en fait un outil incontournable pour toute interaction directe avec K8s.
Helm : Le Gestionnaire de Paquets pour Kubernetes
Imaginez apt ou npm, mais pour Kubernetes. Helm est le gestionnaire de paquets de facto qui vous permet de définir, installer et mettre à niveau des applications Kubernetes complexes. Un « Chart » Helm est un ensemble de fichiers décrivant une application Kubernetes, et il est hautement configurable via des valeurs. Cela simplifie grandement le déploiement d’applications tierces (bases de données, caches, etc.) ou de vos propres applications standardisées.
Environnements de Développement Locaux : Minikube, K3s, Kind
Pour développer et tester localement sans les coûts d’un cluster cloud, des outils comme Minikube, K3s et Kind sont essentiels. Minikube exécute un cluster Kubernetes à nœud unique sur votre machine locale. K3s est une distribution légère de Kubernetes. Kind (Kubernetes in Docker) exécute des clusters Kubernetes sous forme de conteneurs Docker. Ces outils permettent aux développeurs d’itérer rapidement sur leurs configurations K8s.
Observabilité : Prometheus et Grafana
Pour comprendre ce qui se passe dans votre cluster et vos applications, l’observabilité est cruciale. Prometheus est un système de surveillance et d’alertes open source qui collecte des métriques de vos applications et du cluster lui-même. Grafana est une plateforme d’analyse et de visualisation qui s’intègre parfaitement avec Prometheus pour créer des tableaux de bord interactifs, vous donnant une visibilité en temps réel sur la performance et la santé de votre infrastructure.

Ces outils, parmi tant d’autres, composent un écosystème riche qui facilite l’adoption et l’exploitation de Kubernetes. Choisir les bons outils pour votre stack peut considérablement améliorer la productivité de votre équipe et la robustesse de vos déploiements.
POINT CLÉ
L’écosystème Kubernetes est vaste. Des outils comme kubectl pour la CLI, Helm pour la gestion de paquets, Minikube pour le développement local et Prometheus/Grafana pour l’observabilité sont essentiels pour une expérience développeur optimale en 2026.
PERSPECTIVES
Perspectives d’Évolution et Tendances Futures
Kubernetes est une technologie en constante évolution. Pour rester pertinent en 2026 et au-delà, il est important de surveiller les tendances émergentes et les innovations qui façonneront son futur.
Serverless et Kubernetes (Knative)
L’intégration du paradigme serverless avec Kubernetes gagne du terrain. Des projets comme Knative transforment Kubernetes en une plateforme serverless, permettant aux développeurs de déployer des fonctions et des conteneurs sans se soucier de l’infrastructure sous-jacente. Cela combine la flexibilité et le contrôle de K8s avec la simplicité et la scalabilité à la demande du serverless, idéal pour les microservices événementiels.
Kubernetes à la Périphérie (Edge Computing)
Avec la prolifération des appareils IoT et le besoin de traitement des données en temps réel, Kubernetes s’étend vers l’edge computing. Des distributions légères comme K3s sont parfaitement adaptées pour gérer des clusters à petite échelle sur des sites distants ou des appareils périphériques, permettant aux applications de s’exécuter plus près de la source des données et de réduire la latence.
Sécurité Avancée et Politiques (OPA, Kyverno)
La sécurité reste une préoccupation majeure. Des outils comme Open Policy Agent (OPA) et Kyverno permettent de définir des politiques de sécurité granulaires et de les appliquer de manière déclarative à travers le cluster. Cela inclut la validation des configurations, la gestion des admissions de Pods, et l’application de bonnes pratiques de sécurité par défaut, renforçant la posture de sécurité de l’ensemble de l’infrastructure.
IA et Machine Learning sur K8s
Kubernetes est de plus en plus utilisé comme plateforme pour l’intelligence artificielle et le machine learning. Des frameworks comme Kubeflow permettent de déployer et de gérer des pipelines de ML complets sur K8s, de la préparation des données à l’entraînement des modèles et au déploiement en production. La capacité de Kubernetes à gérer des charges de travail intensives et à scaler dynamiquement en fait un choix naturel pour ces applications gourmandes en ressources.

Ces évolutions démontrent que Kubernetes n’est pas une technologie statique, mais une fondation robuste qui s’adapte aux besoins changeants de l’industrie. En restant informé de ces tendances, vous pourrez anticiper les futures exigences et
Articles connexes
- [DevOps & Cloud] Optimiser les coûts de votre infrastructure Cloud en 2026 : Guide pratique pour développeurs
- [DevOps & Cloud] Docker pour développeurs en 2026 : Guide complet de la conteneurisation de vos applications
- [DevOps & Cloud] Monitoring complet avec Prometheus et Grafana en 2026 : Guide pratique