

RÉSUMÉ
[IA & ML] Détection d’objets en temps réel avec YOLO et Python en 2026 : Guide complet
Maîtrisez la détection d’objets en temps réel avec YOLO et Python. Découvrez un guide complet pour implémenter cette technologie IA essentielle dans vos projets pratiques.
Keywords: YOLO, Python, Détection d’Objets
TABLE DES MATIÈRES
1. Contexte et Importance de la Détection d’Objets en Temps Réel
2. Comprendre YOLO : Architecture et Évolution
3. Préparation des Données et Entraînement des Modèles
4. Implémentation Pratique : Détection d’Objets avec YOLO et Python
5. Optimisation et Résolution des Défis Communs
6. Cas d’Usage et Applications Concrètes de YOLO
7. Foire Aux Questions (FAQ)
8. Conclusion et Perspectives Futures
INTRODUCTION
1. Contexte et Importance de la Détection d’Objets en Temps Réel
Dans le paysage technologique en constante évolution de 2026, la détection d’objets en temps réel est devenue une pierre angulaire de l’intelligence artificielle et de la vision par ordinateur. Cette capacité à identifier et localiser des objets spécifiques dans des images ou des flux vidéo en direct, avec une latence minimale, transforme radicalement de nombreux secteurs. Des véhicules autonomes qui naviguent avec précision aux systèmes de surveillance intelligents qui renforcent la sécurité, en passant par les chaînes de production automatisées qui optimisent l’efficacité, l’impact est omniprésent et profond.
L’analyse en temps réel permet aux systèmes de prendre des décisions instantanées et d’interagir avec leur environnement de manière dynamique. Imaginez un drone inspectant des infrastructures critiques, capable de détecter des fissures ou des anomalies structurelles en quelques millisecondes, ou un robot d’entrepôt identifiant et triant des colis sans interruption. Ces scénarios, autrefois de la science-fiction, sont aujourd’hui une réalité grâce à des avancées significatives dans les algorithmes de détection.
Au cœur de cette révolution se trouve le framework YOLO (You Only Look Once), qui s’est imposé comme une référence en matière de vitesse et de précision. Sa capacité à traiter des images entières en une seule passe, contrairement aux approches plus anciennes qui scannaient les images par régions, lui confère un avantage décisif pour les applications en temps réel. Avec l’évolution rapide de Python et de ses bibliothèques d’IA, implémenter et déployer des solutions YOLO est plus accessible que jamais pour les développeurs et les entreprises.
POINT CLÉ
La détection d’objets en temps réel est cruciale en 2026 pour l’automatisation, la sécurité et l’optimisation dans des secteurs variés, et YOLO est le leader incontesté grâce à sa vitesse et sa précision.
Chez Kwontenu, nous nous engageons à démystifier ces technologies complexes pour vous. Cet article vous guidera à travers les principes fondamentaux de YOLO, son évolution jusqu’en 2026, et vous fournira un guide pratique pour l’implémenter avec Python. Que vous soyez un développeur expérimenté cherchant à intégrer la détection d’objets dans un nouveau projet, ou un passionné d’IA désireux de comprendre les rouages de cette technologie, ce guide complet est fait pour vous.
ANALYSE DÉTAILLÉE
2. Comprendre YOLO : Architecture et Évolution
YOLO, l’acronyme de « You Only Look Once », a révolutionné le domaine de la détection d’objets en proposant une approche unifiée. Contrairement aux systèmes traditionnels qui décomposent le problème en plusieurs étapes (proposition de régions, classification, ajustement des boîtes englobantes), YOLO traite l’image entière en une seule passe à travers un réseau neuronal. Cette unicité de traitement est ce qui lui confère sa vitesse inégalée, cruciale pour les applications en temps réel.
Principes Fondamentaux de l’Architecture YOLO
Au cœur de YOLO, une image est divisée en une grille de S x S cellules. Si le centre d’un objet tombe dans une cellule particulière, cette cellule est responsable de la détection de cet objet. Pour chaque cellule de la grille, YOLO prédit un nombre fixe de boîtes englobantes (bounding boxes), la confiance que chaque boîte contient un objet, et les probabilités de classe pour cet objet. Chaque boîte englobante est caractérisée par ses coordonnées (x, y, largeur, hauteur) et un score de confiance.
La « confiance » reflète deux aspects : la probabilité que la boîte contienne un objet et la précision de la boîte prédite par rapport à l’objet réel (mesurée par l’Intersection sur Union, IoU). Les probabilités de classe indiquent la probabilité que l’objet détecté appartienne à une classe spécifique (par exemple, « personne », « voiture », « chat »). Le modèle produit ainsi directement toutes les informations nécessaires pour la détection en une seule inférence, éliminant les goulots d’étranglement des approches multi-étapes.
Évolution de YOLO : Des Prémices à 2026
Depuis sa première apparition en 2015 avec YOLOv1, le framework a connu une évolution remarquable, chaque nouvelle version apportant des améliorations significatives en termes de vitesse, de précision et de robustesse. Les versions initiales comme YOLOv1, YOLOv2 (YOLO9000) et YOLOv3 ont posé les bases, introduisant des concepts comme les ancres (anchor boxes) et des backbones plus performants comme Darknet-53.
En 2026, les versions dominantes sont souvent basées sur les avancées faites par Ultralytics, avec des modèles comme YOLOv5 et surtout YOLOv8, qui intègrent les dernières innovations en matière de réseaux neuronaux. YOLOv8, lancé en 2023, a introduit des améliorations architecturales majeures, une approche sans ancres (anchor-free) pour une meilleure flexibilité, et des fonctions de perte optimisées, menant à des performances supérieures sur un large éventail de tâches de vision par ordinateur, y compris la segmentation et la classification.
POINT CLÉ
YOLOv8, souvent utilisé via le framework Ultralytics, représente l’état de l’art en 2026, offrant un équilibre optimal entre vitesse et précision grâce à des architectures modernes et des techniques d’entraînement avancées.
Les efforts de recherche continuent de pousser les limites, avec des versions expérimentales qui explorent l’intégration de mécanismes d’attention (inspirés des Transformers), des architectures de type « vision transformer » adaptées à la détection, et des modèles encore plus légers pour les déploiements sur des appareils à ressources limitées. En 2026, la tendance est à des modèles plus « prêts à l’emploi », avec des outils d’entraînement et de déploiement simplifiés.
Comparaison avec d’Autres Modèles de Détection d’Objets
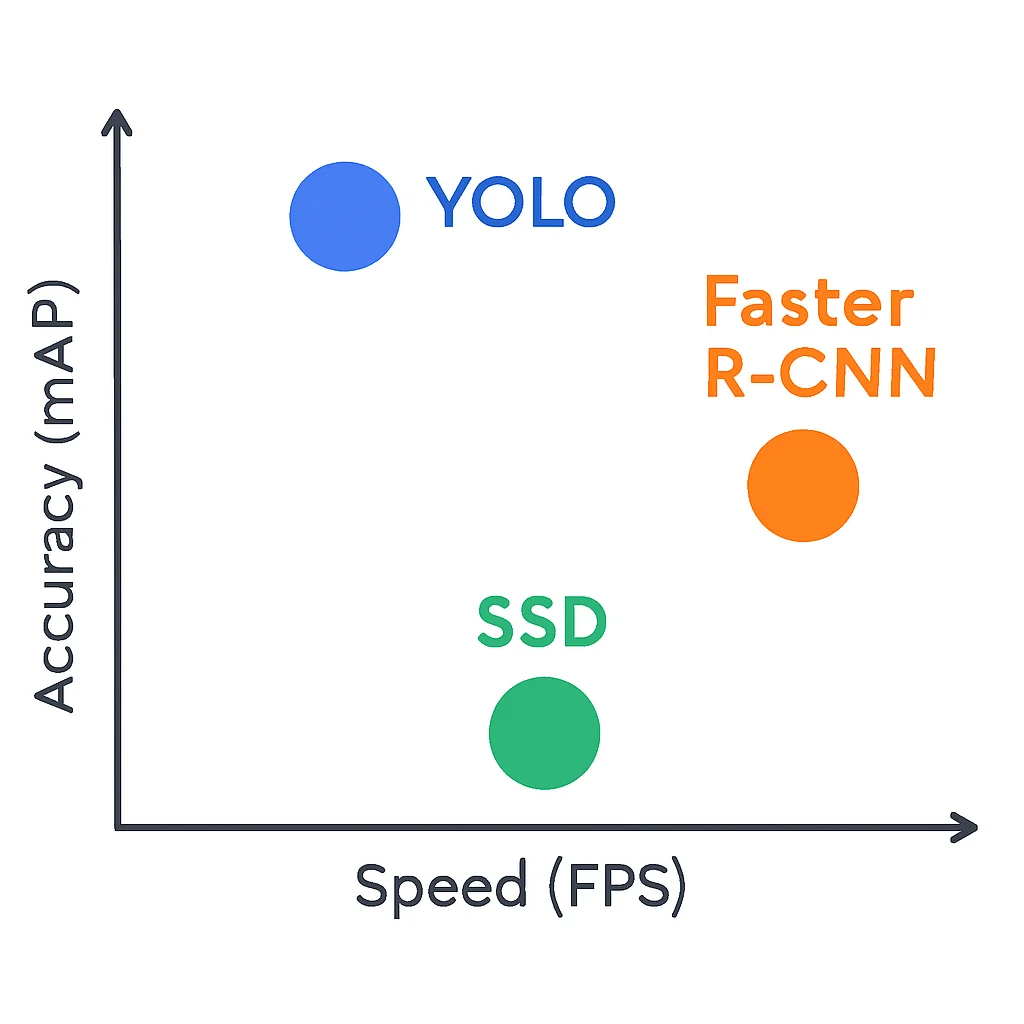
Pour apprécier pleinement la puissance de YOLO, il est utile de le comparer à d’autres architectures populaires comme Faster R-CNN (un détecteur à deux étapes) et SSD (Single Shot MultiBox Detector, également à une étape).
| Caractéristique | YOLO (ex: YOLOv8) | Faster R-CNN | SSD |
|---|---|---|---|
| Approche | Réseau unique, une étape | Réseau à deux étapes (R-CNN + RPN) | Réseau unique, une étape |
| Vitesse d’inférence | Très rapide (60+ FPS sur GPU) | Modérée (5-10 FPS sur GPU) | Rapide (20-30 FPS sur GPU) |
| Précision (mAP) | Très élevée, comparable aux modèles à deux étapes | Excellente, souvent la référence | Bonne, légèrement inférieure à YOLO/Faster R-CNN |
| Complexité d’implémentation | Relativement simple avec des frameworks comme Ultralytics | Plus complexe, nécessite une gestion du RPN | Modérée |
| Taille du modèle | Varie (nano, small, medium, large, xlarge) | Généralement plus grand | Varie, tend à être plus petit que Faster R-CNN |
Comme le montre le tableau, YOLO se distingue par sa vitesse d’inférence, le rendant idéal pour les applications en temps réel où chaque milliseconde compte. Si Faster R-CNN peut offrir une précision marginalement supérieure dans certains scénarios complexes, son coût computationnel le rend moins adapté aux contraintes de temps réel. SSD offre un bon compromis, mais YOLOv8 a souvent surpassé ses performances en 2026, notamment en termes de mAP (mean Average Precision) et de flexibilité.
TRAVAIL PRÉPARATOIRE
3. Préparation des Données et Entraînement des Modèles
La qualité et la pertinence de votre ensemble de données sont les piliers de la performance d’un modèle de détection d’objets. Un modèle YOLO, aussi sophistiqué soit-il, ne peut pas apprendre à détecter ce qu’il n’a jamais vu ou ce qui est mal annoté. Cette section explore les étapes cruciales de la préparation des données et les considérations pour l’entraînement.
Collecte et Annotation des Données
La première étape consiste à collecter un ensemble d’images ou de vidéos représentatives des objets que vous souhaitez détecter et des environnements dans lesquels la détection aura lieu. Pour un projet de détection de piétons, par exemple, il faudra des images de rues, de trottoirs, dans diverses conditions d’éclairage (jour, nuit), météorologiques (pluie, soleil) et sous différents angles de vue. La diversité est clé pour la robustesse du modèle.
Une fois les données brutes collectées, l’étape suivante est l’annotation. Il s’agit de dessiner des boîtes englobantes autour de chaque objet d’intérêt et de lui attribuer une étiquette de classe. C’est une tâche méticuleuse et chronophage, mais essentielle. Des outils comme LabelImg, RectLabel ou des plateformes collaboratives comme Roboflow simplifient ce processus en fournissant des interfaces graphiques intuitives. Pour YOLO, les annotations sont généralement stockées dans des fichiers texte au format .txt, avec une ligne par objet spécifiant l’ID de la classe et les coordonnées normalisées de la boîte (centre_x, centre_y, largeur, hauteur).
Augmentation des Données (Data Augmentation)
L’augmentation des données est une technique puissante pour augmenter la taille et la diversité de votre dataset d’entraînement sans collecter de nouvelles données. Elle aide à rendre le modèle plus robuste aux variations et à prévenir le surapprentissage. Les techniques courantes incluent :
➤ Rotations et Retournements : Changer l’orientation des images.
➤ Changements de Luminosité et de Contraste : Simuler différentes conditions d’éclairage.
➤ Redimensionnement et Recadrage : Varier la taille et la position des objets.
➤ Ajout de Bruit : Simuler des imperfections de capture.
➤ Mélange d’images (MixUp, CutMix, Mosaic) : Des techniques plus avancées qui combinent plusieurs images et leurs annotations pour créer de nouveaux exemples d’entraînement.
POINT CLÉ
Une annotation précise et une augmentation de données intelligente sont fondamentales pour entraîner un modèle YOLO performant et généralisable, minimisant ainsi le risque de surapprentissage.
Division du Dataset et Entraînement
Avant l’entraînement, le dataset doit être divisé en trois sous-ensembles :
● Ensemble d’entraînement (Training Set) : La majorité des données (généralement 70-80%) utilisées pour que le modèle apprenne les motifs.
● Ensemble de validation (Validation Set) : Une portion plus petite (10-15%) utilisée pour évaluer les performances du modèle pendant l’entraînement et ajuster les hyperparamètres.
● Ensemble de test (Test Set) : Une portion séparée (10-15%) utilisée pour une évaluation finale et impartiale des performances du modèle après l’entraînement.
L’entraînement d’un modèle YOLO implique l’optimisation des poids du réseau neuronal à l’aide d’un algorithme d’optimisation (comme SGD ou Adam) et d’une fonction de perte qui mesure l’écart entre les prédictions du modèle et les annotations réelles. Ce processus est itératif, se déroulant sur un certain nombre d’époques, avec des ajustements des hyperparamètres comme le taux d’apprentissage (learning rate) et la taille du lot (batch size).
En 2026, l’entraînement est souvent facilité par l’utilisation de modèles pré-entraînés sur de grands datasets génériques (comme COCO). Cette technique de transfer learning permet de réduire considérablement le temps et les ressources nécessaires pour entraîner un modèle performant sur un dataset personnalisé, car le modèle a déjà appris à reconnaître des caractéristiques visuelles de bas niveau.
GUIDE PRATIQUE
4. Implémentation Pratique : Détection d’Objets avec YOLO et Python
Passons maintenant à l’aspect le plus excitant : l’implémentation pratique de la détection d’objets avec YOLO et Python. Nous nous concentrerons sur l’utilisation de la bibliothèque ultralytics, qui fournit une interface simple et puissante pour les modèles YOLOv8 et au-delà.
Mise en Place de l’Environnement de Développement
Assurez-vous d’avoir Python 3.9 ou une version ultérieure installée. Il est fortement recommandé d’utiliser un environnement virtuel pour gérer les dépendances de votre projet.
EXPLICATION DU CODE
Ces commandes initialisent un environnement virtuel Python et installent les bibliothèques nécessaires : ultralytics pour les modèles YOLO et opencv-python pour le traitement d’images et de vidéos.
# Créer et activer un environnement virtuel (si vous n'en avez pas)
python -m venv yolov8_env
source yolov8_env/bin/activate # Sur Linux/macOS
# yolov8_env\Scripts\activate # Sur Windows
# Installer les dépendances
pip install ultralytics opencv-python numpy
Si vous disposez d’un GPU compatible CUDA, assurez-vous que les pilotes NVIDIA sont à jour et que CUDA Toolkit et cuDNN sont correctement configurés. ultralytics détectera et utilisera automatiquement votre GPU si tout est correctement installé, offrant un gain de performance considérable.
Détection d’Objets sur une Image Statique
L’inférence sur une image est la manière la plus simple de commencer. Nous allons charger un modèle YOLOv8 pré-entraîné sur le dataset COCO (Common Objects in Context), capable de détecter 80 classes d’objets courantes.
EXPLICATION DU CODE
Ce script charge un modèle YOLOv8 pré-entraîné, effectue une détection sur une image locale nommée "bus.jpg", puis affiche l’image avec les boîtes englobantes et les étiquettes. Les résultats sont également sauvegardés dans un dossier 'runs/detect'.
from ultralytics import YOLO
import cv2
import os
# Charger un modèle YOLOv8 pré-entraîné
model = YOLO('yolov8n.pt') # 'n' pour nano, le plus petit et rapide
# Chemin vers l'image à traiter
image_path = 'bus.jpg' # Assurez-vous d'avoir une image 'bus.jpg' dans le même répertoire
# Effectuer la détection sur l'image
results = model(image_path) # Les résultats contiennent les détections
# Afficher les résultats (boîtes, classes, confiances)
for r in results:
im_array = r.plot() # plot les boîtes sur l'image
im = cv2.cvtColor(im_array, cv2.COLOR_RGB2BGR) # Convertir RGB en BGR pour OpenCV
cv2.imshow('YOLOv8 Detection', im)
cv2.waitKey(0) # Attendre une touche pour fermer la fenêtre
cv2.destroyAllWindows()
# Sauvegarder l'image avec les détections
# Les résultats sont automatiquement sauvegardés dans 'runs/detect/expX'
print(f"Résultats sauvegardés dans : {os.path.join(model.predictor.save_dir, image_path)}")
print("Détection sur image terminée.")
Ce code simple démontre la facilité avec laquelle on peut utiliser un modèle YOLOv8 pour la détection. Le modèle yolov8n.pt (nano) est idéal pour les tests rapides et les déploiements sur des appareils moins puissants, tandis que des modèles plus grands comme yolov8m.pt (medium) ou yolov8x.pt (extra large) offrent une meilleure précision au détriment de la vitesse.
POINT CLÉ
La bibliothèque ultralytics simplifie grandement l’utilisation des modèles YOLO, permettant des inférences rapides avec seulement quelques lignes de code Python.
Détection d’Objets en Temps Réel à partir d’un Flux Vidéo (Webcam)
Pour la détection en temps réel, nous allons adapter le code précédent pour traiter des flux vidéo, par exemple depuis une webcam.
EXPLICATION DU CODE
Ce script initialise la capture vidéo à partir de la webcam (index 0), charge le modèle YOLOv8, puis traite chaque trame du flux vidéo en temps réel. Les détections sont affichées dans une fenêtre et le traitement continue jusqu’à ce que la touche ‘q’ soit pressée.
from ultralytics import YOLO
import cv2
# Charger un modèle YOLOv8 pré-entraîné
model = YOLO('yolov8n.pt')
# Ouvrir la webcam (0 est généralement l'ID de la webcam par défaut)
cap = cv2.VideoCapture(0)
if not cap.isOpened():
print("Erreur : Impossible d'ouvrir la webcam ou le fichier vidéo.")
exit()
while True:
ret, frame = cap.read() #