

RÉSUMÉ
Maîtriser les queues de messages en 2026
Guide complet pour architecturer des systèmes backend performants et résilients avec RabbitMQ, Kafka et AWS SQS.
Keywords: Queues de messages, Systèmes distribués, Backend scalabilité
TABLE DES MATIÈRES
1. Introduction : L’Indispensable Rôle des Queues de Messages en 2026
2. RabbitMQ : Le Courtier de Messages Robuste et Polyvalent
3. Apache Kafka : La Plateforme de Streaming d’Événements Haut Débit
4. AWS SQS : La Queue de Messages Gérée et Sans Serveur
5. Analyse Comparative : Choisir la Bonne Technologie pour Votre Projet
6. Résolution de Problèmes Courants et Bonnes Pratiques
7. Application Pratique : Implémentation d’une Architecture Événementielle
8. Conclusion : Vers des Backends Plus Résilients et Scalables
9. Foire Aux Questions (FAQ)
1. Introduction : L’Indispensable Rôle des Queues de Messages en 2026
Dans le paysage technologique en constante évolution de 2026, la construction de systèmes backend performants, résilients et hautement scalables est plus cruciale que jamais. Les architectures monolithiques cèdent de plus en plus la place aux microservices et aux systèmes distribués, poussés par le besoin d’agilité, de flexibilité et de tolérance aux pannes. Au cœur de cette transformation se trouvent les queues de messages, des composants fondamentaux qui permettent à différentes parties d’un système de communiquer de manière asynchrone et découplée.
Imaginez un scénario où votre application e-commerce reçoit des milliers de commandes par minute lors d’un événement promotionnel. Si chaque commande déclenche directement une série d’opérations (mise à jour de l’inventaire, traitement du paiement, envoi d’e-mails de confirmation, mise à jour du CRM), votre serveur risque d’être rapidement submergé. Les queues de messages résolvent ce problème en agissant comme des tampons. Au lieu de traiter immédiatement chaque tâche, l’application place simplement un « message » (représentant une commande) dans une file d’attente, puis continue à accepter de nouvelles requêtes. Des processus distincts (les « consommateurs ») peuvent ensuite extraire et traiter ces messages à leur propre rythme, garantissant que le système reste réactif et stable, même sous de lourdes charges.
Ce mécanisme offre plusieurs avantages clés : le découplage des services, ce qui signifie que les producteurs et les consommateurs n’ont pas besoin d’être disponibles simultanément ou de connaître l’existence de l’autre ; l’amélioration de la résilience, car les messages sont stockés en toute sécurité jusqu’à ce qu’ils soient traités, évitant ainsi la perte de données en cas de panne d’un service ; et une scalabilité accrue, car vous pouvez facilement ajouter plus de consommateurs pour gérer une charge de travail croissante sans affecter les producteurs. De plus, les queues de messages facilitent la gestion des pics de trafic, la priorisation des tâches et l’implémentation de modèles de communication complexes comme le « publish-subscribe ».
POINT CLÉ
Les queues de messages sont le ciment des architectures distribuées modernes, permettant découplage, résilience et scalabilité. Elles transforment la communication synchrone et fragile en un échange asynchrone et robuste.
Dans cet article, nous plongerons dans trois des solutions de queues de messages les plus populaires et les plus influentes en 2026 : RabbitMQ, Apache Kafka et AWS SQS. Nous explorerons leurs architectures, leurs cas d’utilisation optimaux, leurs forces et leurs faiblesses, et fournirons des exemples concrets pour vous aider à maîtriser ces technologies essentielles pour tout développeur backend.
2. RabbitMQ : Le Courtier de Messages Robuste et Polyvalent
RabbitMQ est un courtier de messages open source largement adopté, implémentant le protocole Advanced Message Queuing Protocol (AMQP). Il est réputé pour sa flexibilité, sa robustesse et sa capacité à gérer des modèles de messagerie complexes. Contrairement à Kafka qui est une plateforme de streaming d’événements, RabbitMQ est avant tout un courtier de messages traditionnel, conçu pour la livraison fiable de messages individuels entre applications.
Architecture et Fonctionnement
Au cœur de RabbitMQ se trouve le concept d’échange (exchange) et de queue (queue). Les producteurs envoient des messages à un échange, qui est ensuite responsable de router ces messages vers une ou plusieurs queues en fonction de règles spécifiques (bindings). Les consommateurs se connectent à ces queues et récupèrent les messages pour les traiter. Cette architecture permet un découplage fort entre producteurs et consommateurs.
Principales Caractéristiques de RabbitMQ
Robustesse — Supporte la persistance des messages sur disque, garantissant qu’ils ne sont pas perdus en cas de redémarrage du courtier.
Fiabilité — Utilise des accusés de réception (acknowledgements) pour s’assurer qu’un message a bien été traité par un consommateur avant d’être supprimé de la queue.
Routage Flexible — Offre différents types d’échanges (direct, fanout, topic, headers) pour des modèles de routage sophistiqués.
Haute Disponibilité — Peut être déployé en cluster pour une tolérance aux pannes et une haute disponibilité.
Cas d’Utilisation Typiques
- Traitement de Tâches en Arrière-plan : Envoi de notifications, redimensionnement d’images, traitements longs qui ne doivent pas bloquer l’interface utilisateur. Par exemple, après l’inscription d’un utilisateur, un message est envoyé à RabbitMQ pour déclencher l’envoi d’un e-mail de bienvenue.
- Communication entre Microservices : Découplage des services où un service publie des événements et d’autres services les consomment. Un service de commande peut publier « NouvelleCommandeCréée », et un service de facturation ainsi qu’un service d’inventaire peuvent y souscrire.
- RPC Asynchrone : Implémentation de requêtes/réponses asynchrones entre des services. Un service peut envoyer une requête à un autre via une queue, et le résultat est renvoyé via une queue de réponse dédiée.
Exemple de Code Python avec Pika
Voici un exemple simple de producteur et de consommateur utilisant la bibliothèque Pika pour interagir avec RabbitMQ. Le producteur envoie un message à un échange de type ‘fanout’, qui le diffuse à toutes les queues qui y sont liées.
EXPLICATION DU CODE
Le code ci-dessous montre un producteur qui envoie le message « Bonjour, Kwontenu! » à un échange nommé logs de type fanout. Le consommateur déclare une queue temporaire, la lie à cet échange et écoute les messages, les affichant une fois reçus.
# producteur.py
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='logs', exchange_type='fanout')
message = "Bonjour, Kwontenu! Ceci est un message de test."
channel.basic_publish(exchange='logs', routing_key='', body=message)
print(f" [x] Message envoyé: '{message}'")
connection.close()
# consommateur.py
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='logs', exchange_type='fanout')
result = channel.queue_declare(queue='', exclusive=True)
queue_name = result.method.queue
channel.queue_bind(exchange='logs', queue=queue_name)
print(' [*] En attente de messages. Pour quitter, appuyez sur CTRL+C')
def callback(ch, method, properties, body):
print(f" [x] Message reçu: {body.decode()}")
ch.basic_ack(delivery_tag=method.delivery_tag) # Accusé de réception
channel.basic_consume(queue=queue_name, on_message_callback=callback)
channel.start_consuming()
Avantages de RabbitMQ
✓ Maturité et Communauté : Existe depuis longtemps, documentation riche, grande communauté.
✓ Routage Sophistiqué : Flexibilité inégalée pour diriger les messages vers des destinations spécifiques.
✓ Fiabilité : Accusés de réception et persistance garantissent une livraison « at least once ».
✓ Facilité d’Utilisation : Relativement simple à installer et à gérer pour des cas d’utilisation standard.
Inconvénients de RabbitMQ
✗ Débit Moins Élevé : Moins adapté aux charges de travail de streaming massives par rapport à Kafka.
✗ Complexité Opérationnelle : La gestion d’un cluster RabbitMQ peut être complexe pour des déploiements à grande échelle.
✗ Pas de Rétention Longue : Les messages sont supprimés après consommation, ce n’est pas un journal d’événements.
3. Apache Kafka : La Plateforme de Streaming d’Événements Haut Débit
Apache Kafka est bien plus qu’une simple queue de messages ; c’est une plateforme de streaming d’événements distribuée, conçue pour gérer des flux de données en temps réel à très grande échelle. Développé initialement par LinkedIn, Kafka est devenu la référence pour les architectures événementielles, le traitement de données en temps réel et les pipelines de données.
Architecture Log-Centric
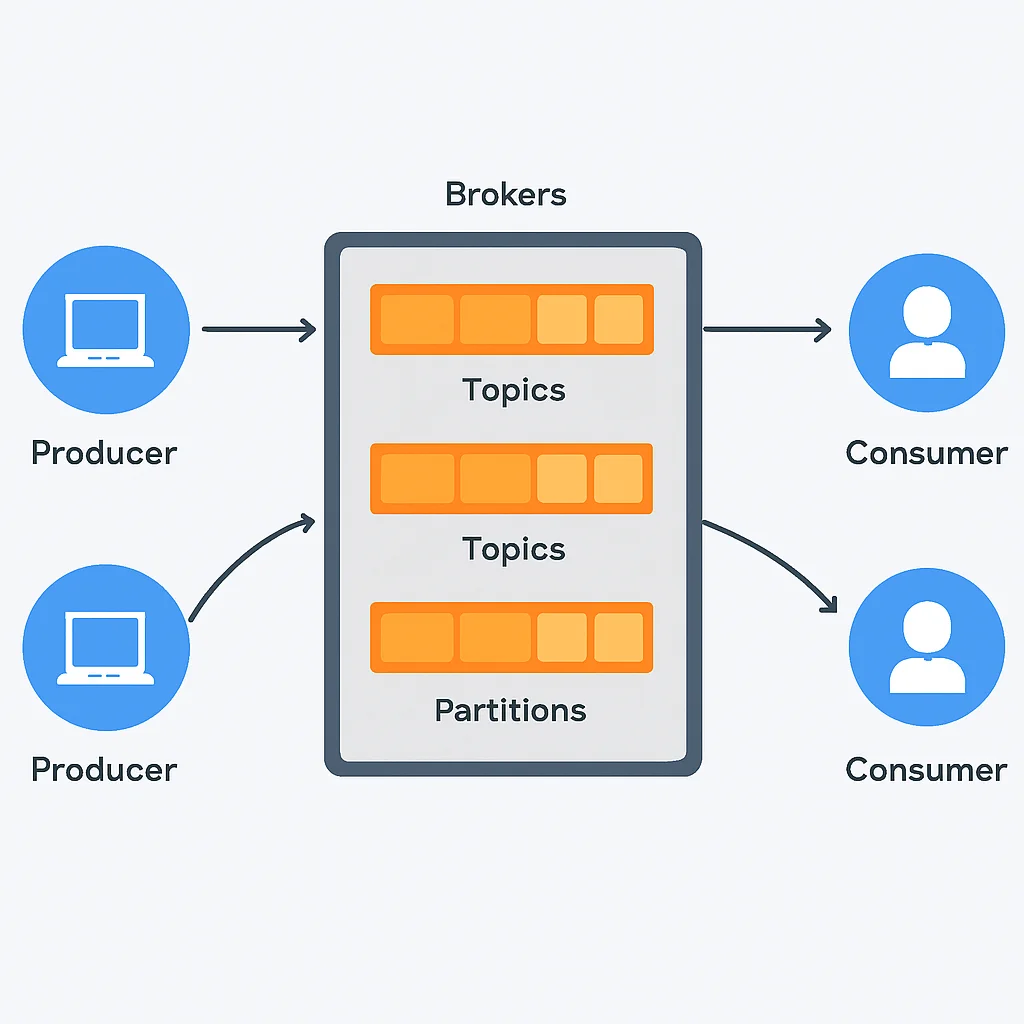
L’architecture de Kafka est fondamentalement différente de celle de RabbitMQ. Au lieu de queues éphémères, Kafka utilise des « topics » qui sont divisés en « partitions ». Chaque partition est un journal d’événements ordonné et immuable. Les messages (ou « enregistrements ») sont ajoutés à la fin du journal et sont conservés pendant une période configurable (par exemple, 7 jours, 30 jours, ou indéfiniment). Les consommateurs maintiennent leur propre « offset » (position) dans le journal, ce qui leur permet de lire les messages à leur propre rythme, de rejouer des événements passés, ou de reprendre la lecture après une panne.
POINT CLÉ
Kafka est une plateforme de streaming, pas seulement une queue. Son architecture basée sur des journaux immuables permet une relecture des événements, une rétention longue et un débit massif, idéal pour l’event sourcing et l’analyse en temps réel.
Composants Clés
- Producteurs : Envoient des messages aux topics Kafka.
- Consommateurs : Lisent les messages des topics. Ils opèrent au sein de « groupes de consommateurs », où chaque message dans une partition est consommé par un seul membre du groupe.
- Brokers : Les serveurs Kafka qui stockent les journaux de partitions et gèrent les requêtes des producteurs et des consommateurs.
- ZooKeeper (ou KRaft depuis Kafka 2.8+) : Gère les métadonnées du cluster, la découverte des brokers et l’état des partitions. KRaft vise à supprimer la dépendance à ZooKeeper.
Cas d’Utilisation Typiques
- Event Sourcing : Enregistrement de tous les changements d’état d’une application comme une séquence d’événements.
- Pipelines de Données et ETL en Temps Réel : Ingestion et transformation de grands volumes de données provenant de diverses sources vers des bases de données ou des entrepôts de données. Par exemple, collecte de logs d’application de centaines de serveurs pour une analyse centralisée.
- Traitement de Flux en Temps Réel : Analyse de données en continu pour détecter des anomalies, personnaliser des expériences utilisateur ou réagir à des événements critiques. Un système de détection de fraude peut analyser les transactions bancaires en temps réel.
- Microservices : Communication asynchrone à haut débit, permettant aux services de publier des événements qui sont consommés par d’autres services, souvent avec une rétention pour rejouer l’historique.
Exemple de Code Python avec Confluent Kafka
Voici un exemple simplifié de producteur et de consommateur Kafka en Python, utilisant la bibliothèque confluent-kafka. Ce code suppose un broker Kafka fonctionnant sur localhost:9092.
EXPLICATION DU CODE
Le producteur envoie cinq messages au topic kwontenu_topic, en utilisant un callback pour gérer les accusés de réception. Le consommateur s’abonne à ce même topic, pollue les messages et les affiche, s’assurant de commettre son offset après chaque traitement réussi.
# producteur_kafka.py
from confluent_kafka import Producer
import socket
conf = {
'bootstrap.servers': 'localhost:9092',
'client.id': socket.gethostname()
}
producer = Producer(conf)
def acked(err, msg):
if err is not None:
print(f"Échec de la livraison du message: {err}")
else:
print(f"Message livré au topic {msg.topic()} [{msg.partition()}] @ offset {msg.offset()}")
for i in range(5):
message_key = f"clé-{i}"
message_value = f"Message Kwontenu numéro {i}"
producer.produce("kwontenu_topic", key=message_key, value=message_value, callback=acked)
producer.poll(1) # Déclenche les callbacks
producer.flush()
print("Tous les messages ont été envoyés.")
# consommateur_kafka.py
from confluent_kafka import Consumer, KafkaException, KafkaError
import sys
conf = {
'bootstrap.servers': 'localhost:9092',
'group.id': 'kwontenu_group',
'auto.offset.reset': 'earliest'
}
consumer = Consumer(conf)
try:
consumer.subscribe(['kwontenu_topic'])
while True:
msg = consumer.poll(timeout=1.0)
if msg is None:
continue
if msg.error():
if msg.error().code() == KafkaError._PARTITION_EOF:
sys.stderr.write(f"%% {msg.topic()} [{msg.partition()}] atteint la fin de la partition à l'offset {msg.offset()}\n")
elif msg.error():
raise KafkaException(msg.error())
else:
print(f"Message reçu: Clé='{msg.key().decode()}', Valeur='{msg.value().decode()}'")
# Enregistrez l'offset pour ne pas le traiter à nouveau
consumer.commit(message=msg)
except KeyboardInterrupt:
sys.stderr.write('%% Interruption par l\'utilisateur\n')
finally:
consumer.close()
Avantages de Kafka
✓ Débit Extrêmement Élevé : Conçu pour gérer des millions de messages par seconde.
✓ Scalabilité Horizontale : Facilement scalable en ajoutant des brokers et des partitions.
✓ Rétention des Données : Les messages sont conservés, permettant la relecture et l’analyse historique.
✓ Tolérance aux Pannes : Architecture distribuée avec réplication des partitions pour la résilience.
Inconvénients de Kafka
✗ Complexité Opérationnelle : La gestion d’un cluster Kafka (surtout avec ZooKeeper) est complexe et exigeante en ressources.
✗ Latence Plus Élevée : Peut avoir une latence légèrement plus élevée que RabbitMQ pour des messages individuels.
✗ Moins de Routage Flexible : Le routage est plus simple (par topic/partition) que les échanges complexes de RabbitMQ.
4. AWS SQS : La Queue de Messages Gérée et Sans Serveur
AWS Simple Queue Service (SQS) est un service de queue de messages entièrement géré et sans serveur proposé par Amazon Web Services. Il élimine la complexité opérationnelle liée à la gestion de serveurs de queues, permettant aux développeurs de se concentrer sur la logique métier. SQS est idéal pour les architectures cloud natives et les entreprises qui souhaitent déléguer la gestion de l’infrastructure.
Types de Queues SQS
SQS propose deux types de queues, chacune adaptée à des besoins spécifiques :
- Queues Standard : Offrent un débit maximal, une livraison « at least once » (au moins une fois) et un meilleur effort pour la préservation de l’ordre des messages. Elles sont idéales pour les applications où un ordre strict n’est pas critique, mais où le volume est élevé (par exemple, 100 000 transactions par seconde).
- Queues FIFO (First-In, First-Out) : Garantissent que les messages sont traités une seule fois, dans l’ordre exact où ils sont envoyés et reçus. Elles sont parfaites pour les scénarios où l’ordre des opérations est crucial, comme le traitement des transactions financières ou la mise à jour de l’état d’un inventaire. Les queues FIFO supportent jusqu’à 3 000 messages par seconde avec des groupes de messages, ou 300 messages par seconde sans.
POINT CLÉ
AWS SQS offre une solution de queue de messages entièrement gérée, sans les tracas de l’infrastructure. Les queues Standard sont pour le haut débit avec un ordre « best-effort », tandis que les queues FIFO garantissent l’ordre et la livraison unique pour les cas critiques.
Fonctionnalités Clés
- Visibilité Timeout : Période pendant laquelle un message est invisible pour les autres consommateurs après avoir été récupéré, évitant un traitement multiple.
- Dead-Letter Queues (DLQ) : Permet de rediriger les messages qui ne peuvent pas être traités avec succès vers une queue dédiée pour l’analyse et la gestion des erreurs.
- Long Polling : Réduit l’utilisation du CPU et les coûts en attendant qu’un message arrive dans la queue plutôt que de faire des requêtes fréquentes.
- Intégration AWS : S’intègre nativement avec d’autres services AWS comme Lambda, EC2, SNS, etc.
Cas d’Utilisation Typiques
- Découplage de Microservices : Un service publie des messages dans SQS, et un autre service les consomme de manière asynchrone.
- Traitement par Lots : Des tâches de longue durée peuvent être déchargées vers SQS, et des workers (par exemple, des instances EC2 ou des fonctions Lambda) les traitent en parallèle.
- Planification de Tâches : Les messages peuvent être envoyés avec un délai pour être traités ultérieurement.
- Gestion des Commandes : Dans un système e-commerce, les commandes peuvent être placées dans une queue FIFO pour garantir un traitement ordonné et unique.
Exemple de Code Python avec Boto3 (AWS SDK)
Voici comment interagir avec SQS en utilisant le SDK AWS pour Python, Boto3. Cet exemple montre l’envoi et la réception d’un message.
EXPLICATION DU CODE
Le producteur envoie un message simple à une queue SQS nommée KwontenuTestQueue. Le consommateur interroge ensuite cette queue, reçoit le message, l’affiche, puis le supprime pour éviter qu’il ne soit traité à nouveau. Notez la création de la queue si elle n’existe pas.
# sqs_interaction.py
import boto3
import json
import time
# Assurez-vous d'avoir configuré vos identifiants AWS
# aws configure
sqs = boto3.client('sqs', region_name='eu-west-1') # Remplacez par votre région
queue_name = 'KwontenuTestQueue'
try:
response = sqs.get_queue_url(QueueName=queue_name)
queue_url = response['QueueUrl']
except sqs.exceptions.QueueDoesNotExist:
print(f"La queue '{queue_name}' n'existe pas, création...")
response = sqs.create_queue(
QueueName=queue_name,
Attributes={
'DelaySeconds': '0',
'MessageRetentionPeriod': '345600' # 4 jours
}
)
queue_url = response['QueueUrl']
print(f"Queue '{queue_name}' créée avec l'URL: {queue_url}")
time.sleep(5) # Attendre que la queue soit entièrement disponible
# --- Producteur ---
def send_message(message_body):
response = sqs.send_message(
QueueUrl=queue_url,
MessageBody=json.dumps(message_body)
)
print(f"Message envoyé: {response['MessageId']}")
# --- Consommateur ---
def receive_and_delete_messages():
response = sqs.receive_message(
QueueUrl=queue_url,
MaxNumberOfMessages=1,
WaitTimeSeconds=10 # Long Polling
)
if 'Messages' in response:
for message in response['Messages']:
print(f"Message reçu: {message['Body']}")
sqs.delete_message(
QueueUrl=queue_url,
ReceiptHandle=message['ReceiptHandle']
)
print(f"Message supprimé: {message['MessageId']}")
else:
print("Aucun message dans la queue.")
if __name__ == "__main__":
print("\n--- Envoi d'un message ---")
send_message({"event_type": "user_registered", "user_id": "123", "timestamp": int(time.time())})
print("\n--- Réception et suppression d'un message (attendez 10s pour le long polling) ---")
receive_and_delete_messages()
print("\n--- Réception et suppression d'un message vide (attendez 10s pour le long polling) ---")
receive_and_delete_messages()
Avantages d’AWS SQS
✓ Entièrement Géré : Pas d’infrastructure à gérer, AWS s’occupe de la scalabilité, de la disponibilité et de la maintenance.
✓ Scalabilité Illimitée : S’adapte automatiquement à n’importe quel volume de messages sans configuration manuelle.
✓ Haute Disponibilité : Réplication automatique des messages sur plusieurs zones de disponibilité AWS.
✓ Modèle de Coût Pay-as-you-go : Facturation à l’utilisation (par million de requêtes), très économique pour de nombreux cas.
Inconvénients d’AWS SQS
✗ Dépendance à AWS : Verrouillage fournisseur si vous n’utilisez pas déjà AWS.
✗ Pas de Modèle Pub/Sub Direct : Nécessite AWS SNS pour un vrai modèle pub/sub avec plusieurs abonnés par message.
✗ Rétention Limitée : Les messages sont conservés jusqu’à 14 jours, pas un journal d’événements à long terme comme Kafka.
5. Analyse Comparative : Choisir la Bonne Technologie pour Votre Projet
Le choix entre RabbitMQ, Kafka et AWS SQS dépend largement des exigences spécifiques de votre projet. Il n’y a pas de solution « meilleure » dans l’absolu, mais plutôt la plus adaptée à un contexte donné. Examinons les facteurs clés de différenciation.
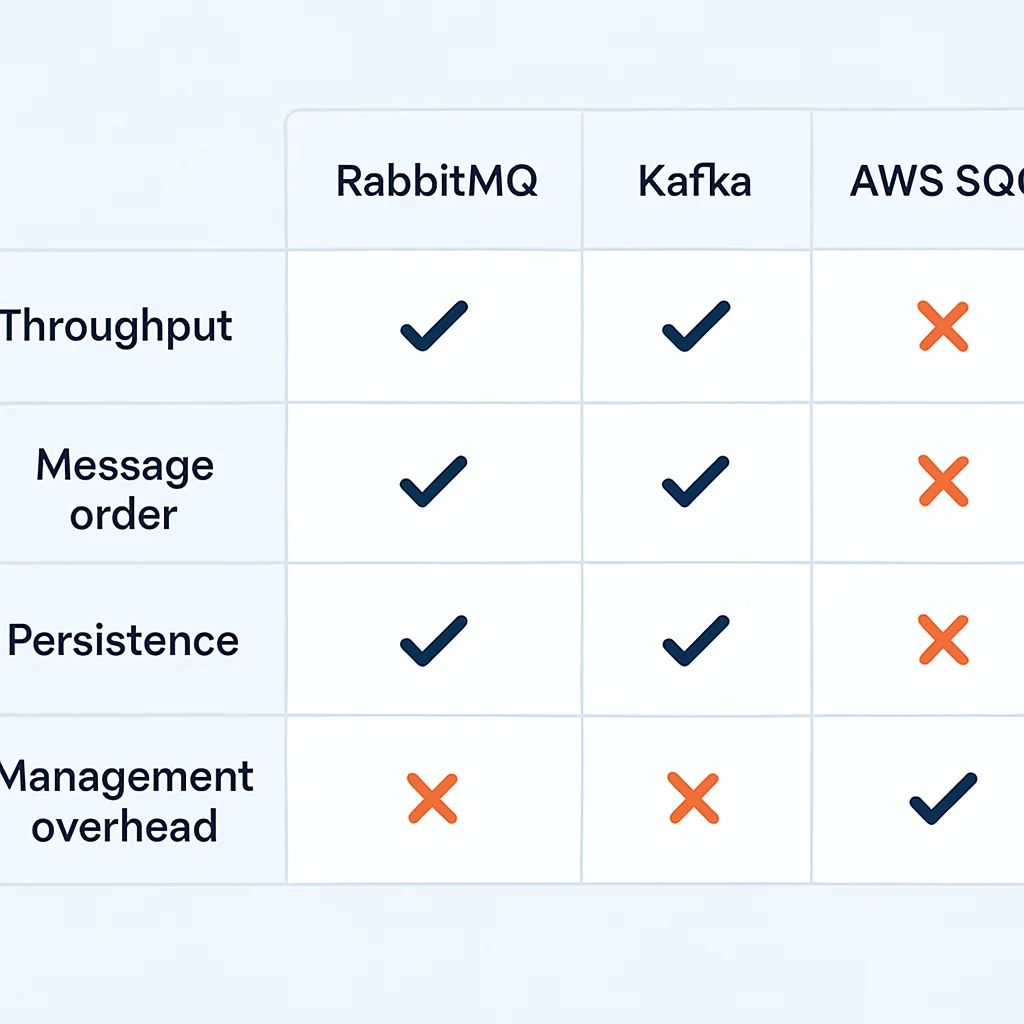
Tableau Comparatif Détaillé
| Caractéristique | RabbitMQ | Apache Kafka | AWS SQS |
|---|---|---|---|
| Type Principal | Courtier de messages (Message Broker) | Plateforme de streaming d’événements (Event Streaming Platform) | Queue de messages gérée (Managed Message Queue) |
| Débit | Modéré à élevé (milliers/s) | Très élevé (millions/s) | Élevé (centaines de milliers/s) |
| Latence | Faible (millisecondes) | Faible à modérée (dizaines de millisecondes) | Faible (millisecondes) |
| Ordre des Messages | Garanti par queue | Garanti par partition | Best-effort (Standard), Garanti (FIFO) |
| Persistance | Oui (sur disque) | Oui (journal d’événements configurable) | Oui (jusqu’à 14 jours) |
| Modèle de Consommation | Message pull/push, message supprimé après ack | Journal pull, offset géré par le consommateur | Message pull, message supprimé après ack |
| Routage | Très flexible (échanges, bindings) | Basé sur le topic et la clé de message | Direct vers la queue (nécessite SNS pour pub/sub) |
| Complexité Opérationnelle | Modérée à élevée | Élevée | Faible (entièrement géré) |
| Coût | Coût d’infrastructure + gestion | Coût d’infrastructure + gestion | Pay-as-you-go (par requête) |
Quand Choisir Quoi ?
- Choisissez RabbitMQ si :
- Vous avez besoin d’un routage de messages complexe et de différents modèles de communication (fanout, direct, topic).
- Vous traitez des tâches asynchrones individuelles avec une livraison fiable (« at least once ») et une faible latence est importante pour chaque message.
- Votre charge de travail est modérée à élevée mais n’atteint pas les millions de messages par seconde en continu.
- Vous préférez une solution auto-hébergée avec un contrôle total sur l’infrastructure.
- Choisissez Apache Kafka si :
- Vous construisez une architecture événementielle avec un besoin de rétention des événements pour rejouer l’historique ou pour l’event sourcing.
- Vous gérez des volumes massifs de données en streaming (plusieurs centaines de milliers, voire millions de messages par seconde).
- Vous avez besoin d’une plateforme unifiée pour l’ingestion de données, le traitement de flux et la persistance des événements.
- La complexité opérationnelle et la gestion d’un cluster distribué sont acceptables pour votre équipe.
- Choisissez AWS SQS si :
- Vous opérez déjà dans l’écosystème AWS et souhaitez une solution entièrement gérée et sans serveur.
- Vous avez besoin d’une scalabilité élastique et illimitée sans vous soucier de la gestion de l’infrastructure.
- Vos cas d’utilisation sont principalement des queues de messages traditionnelles pour le découplage de microservices ou le traitement par lots.
- La simplicité de mise en œuvre et le modèle de coût pay-as-you-go sont prioritaires.
- Vous avez besoin d’un ordre strict et d’une livraison unique pour des messages critiques (avec SQS FIFO).
POINT CLÉ
Le choix technologique doit être guidé par les besoins spécifiques : flexibilité de routage et faible latence par message pour RabbitMQ ; haut débit, rétention longue et traitement de flux pour Kafka ; et simplicité opérationnelle, scalabilité illimitée et intégration cloud pour SQS.
6. Résolution de Problèmes Courants et Bonnes Pratiques
Même avec les meilleures technologies, des défis peuvent survenir lors de l’implémentation et de la gestion des queues de messages. Voici quelques problèmes courants et leurs solutions, applicables à différentes plateformes.
PROBLÈME 01
Perte de Messages
La perte de messages est l’un des problèmes les plus critiques. Elle peut survenir si le courtier tombe en panne avant de persister un message, si un consommateur échoue avant d’accuser réception, ou si les messages expirent.
SOLUTION
Persistance : Assurez-vous que les messages sont persistés sur disque. Pour RabbitMQ, marquez les messages comme delivery_mode=2 (persistent). Kafka et SQS gèrent la persistance par défaut.
Accusés de Réception (ACK) : Les consommateurs doivent accuser réception des messages uniquement après un traitement réussi. En cas d’échec, le message doit être rejeté pour être remis en queue ou envoyé à une DLQ.
Dead-Letter Queues (DLQ) : Configurez des DLQ pour capturer les messages qui ne peuvent pas être traités après plusieurs tentatives. Cela permet d’analyser les erreurs sans bloquer la queue principale.
Réplication : Déployez vos brokers en cluster avec réplication (RabbitMQ, Kafka) ou utilisez des services gérés qui le font automatiquement (SQS).
PROBLÈME 02
Débit Insuffisant et Latence Élevée
Votre système ne parvient pas à traiter les messages assez rapidement, ce qui entraîne un backlog croissant et une dégradation des performances. Cela peut être dû à des goulots d’étranglement côté broker ou consommateur.
SOLUTION
Scalabilité Horizontale : Ajoutez plus de consommateurs pour traiter les messages en parallèle. Pour Kafka, assurez-vous d’avoir suffisamment de partitions pour que les groupes de consommateurs puissent évoluer. Pour SQS, la scalabilité des consommateurs est gérée par votre application (par ex. Lambda concurrentes).
Optimisation des Consommateurs : Vérifiez que le code de vos consommateurs est efficace. Des opérations bloquantes ou des requêtes lentes peuvent ralentir l’ensemble du pipeline. Utilisez des traitements asynchrones si possible.
Batching des Messages : Envoyez ou recevez des messages par lots (batching) lorsque la latence par message n’est pas critique. Cela réduit le nombre de requêtes réseau et améliore le débit global (par exemple, MaxNumberOfMessages dans SQS).
Surveillance et Métriques : Mettez en place une surveillance robuste pour identifier les goulots d’étranglement (latence, taux de messages en file, utilisation CPU/mémoire des brokers/consommateurs).
PROBLÈME 03
Complexité Opérationnelle et Coût
La gestion d’un cluster auto-hébergé (RabbitMQ, Kafka) peut être coûteuse en temps et en ressources humaines, notamment pour la mise à l’échelle, la maintenance, les mises à jour et la résolution des pannes.
SOLUTION
Services Gérés : Envisagez des versions gérées comme AWS SQS, Amazon MSK (Kafka géré), ou des services tiers comme Aiven pour Kafka/RabbitMQ. Cela réduit considérablement la charge opérationnelle.
Automatisation : Pour les déploiements auto-hébergés, utilisez des outils d’Infrastructure as Code (IaC) comme Terraform ou Ansible pour automatiser le déploiement, la configuration et la mise à l’échelle des clusters.
Optimisation des Ressources : Surveillez attentivement l’utilisation des ressources et ajustez la taille des instances ou le nombre de brokers/partitions pour optimiser les coûts sans compromettre les performances.
Sécurité : Implémentez des mécanismes d’authentification et d’autorisation robustes pour contrôler l’accès aux queues et aux topics. Utilisez le chiffrement des données en transit et au repos.
POINT CLÉ
Une gestion efficace des queues de messages repose sur la persistance, les accusés de réception, les DLQ pour la fiabilité ; la scalabilité horizontale et le batching pour le débit ; et l’automatisation ou les services gérés pour réduire la complexité opérationnelle et les coûts.
7. Application Pratique : Implémentation d’une Architecture Événementielle
Pour illustrer concrètement l’utilisation des queues de messages, imaginons que nous transformons un système de gestion de commandes monolithique en une architecture de microservices événementielle. L’objectif est de découpler le processus de commande des opérations secondaires et d’améliorer la scalabilité.
Scénario : Traitement de Commande E-commerce
Initialement, lorsqu’un client passe une commande, le service de commande appelle directement les services de paiement, d’inventaire, de notification par e-mail et d’analyse. En cas de défaillance d’un de ces services, la commande entière peut échouer ou être retardée. Nous allons utiliser Kafka comme plateforme d’événements pour orchestrer ce processus de manière asynchrone.
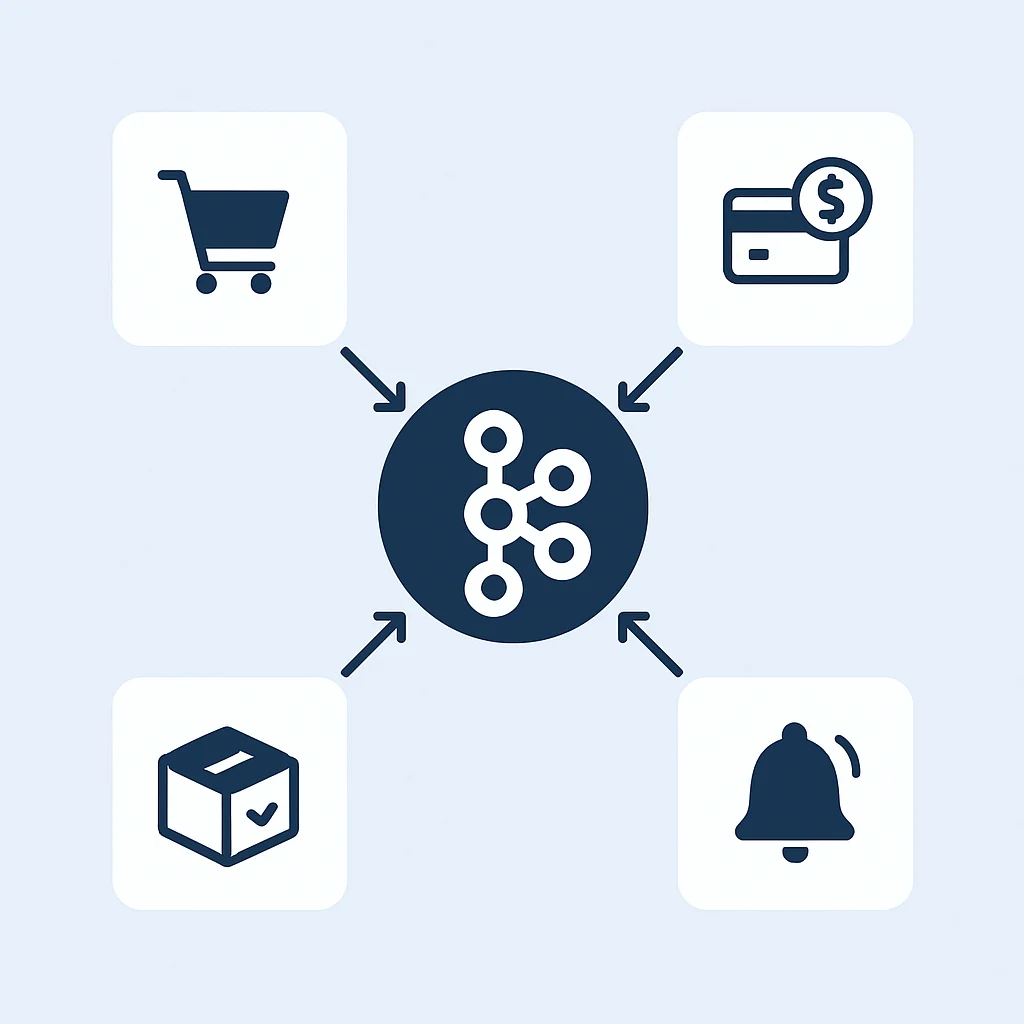
Étapes de la Migration vers une Architecture Événementielle avec Kafka
Étape 1
Le Service de Commande Publie un Événement
Lorsqu’une nouvelle commande est validée, le « Service de Commande » publie un événement CommandeCréée dans un topic Kafka dédié, par exemple commandes.events. Le message contient toutes les informations pertinentes sur la commande (ID, articles, montant, ID client, etc.). Le service de commande n’attend pas de réponse immédiate.
Étape 2
Les Consommateurs Réagissent à l’Événement
Plusieurs services s’abonnent au topic commandes.events :
- Le Service de Paiement consomme l’événement
CommandeCrééepour initier le processus de paiement. Après un succès ou un échec, il publie un événementPaiementRéussiouPaiementÉchouésur un topicpaiements.events. - Le Service d’Inventaire consomme l’événement
CommandeCrééepour décrémenter les stocks. Si l’inventaire est insuffisant, il pourrait publier un événementStockInsuffisant. - Le Service de Notification consomme l’événement
CommandeCrééepour préparer l’envoi d’un e-mail de confirmation. Il attendra un événementPaiementRéussiavant d’envoyer l’e-mail. - Le Service d’Analyse consomme l’événement
CommandeCréée(et d’autres événements) pour mettre à jour les tableaux de bord en temps réel.
Catégories Backend, Développement