

RÉSUMÉ
[Backend] Optimiser la performance de votre API avec le caching en 2026 : Stratégies et implémentation
Ce guide explore les stratégies clés, outils comme Redis et Memcached, et les bonnes pratiques d’implémentation pour un backend rapide et scalable.
Keywords: caching backend, performance API, invalidation cache
TABLE DES MATIÈRES
1. Introduction : L’Impératif de Performance des APIs en 2026
2. Comprendre le Caching : Pourquoi et Où ?
3. Les Stratégies de Caching Courantes
4. Outils de Caching Distribué : Redis vs Memcached
5. Les Défis du Caching : Gestion de l’Invalidation et Cohérence des Données
6. Application Pratique : Implémenter le Caching avec Redis
7. Cas d’Usage Réels du Caching
8. Foire Aux Questions (FAQ)
INTRODUCTION
1. L’Impératif de Performance des APIs en 2026
Dans le paysage numérique ultra-connecté de 2026, la performance des APIs n’est plus un simple avantage concurrentiel, mais une exigence fondamentale. Les utilisateurs s’attendent à des expériences fluides et instantanées, avec des temps de réponse mesurés en millisecondes. Une API lente peut entraîner une perte d’engagement, une baisse des conversions et, in fine, un impact négatif significatif sur les revenus.
Les architectures modernes, souvent basées sur des microservices et des applications distribuées, multiplient les appels API. Chaque milliseconde ajoutée à une requête peut se propager en cascade à travers le système, dégradant l’expérience utilisateur globale. Selon une étude récente de Google, un délai d’une seconde dans le chargement d’une page mobile peut réduire les conversions de 20%. Pour les APIs, cette tolérance est encore plus faible.
C’est là que le caching entre en jeu. Le caching est une technique d’optimisation qui consiste à stocker des copies de données fréquemment consultées dans un emplacement de stockage plus rapide et plus proche de l’utilisateur ou de l’application. En évitant de refaire des calculs coûteux ou des requêtes à la base de données pour des données qui n’ont pas changé, le caching réduit drastiquement la latence et la charge sur les serveurs backend et les bases de données.
En 2026, avec l’explosion de l’IA, de l’IoT et des applications en temps réel, la demande de données est sans précédent. Le caching devient un pilier essentiel pour construire des architectures backend résilientes, scalables et économiques. Il permet non seulement d’améliorer la vitesse, mais aussi de réduire les coûts d’infrastructure en diminuant la charge sur les ressources plus chères (comme les bases de données ou les services de calcul intensif).
POINT CLÉ
En 2026, le caching est une stratégie indispensable pour garantir des APIs performantes, réduire la latence, améliorer l’expérience utilisateur et optimiser les coûts d’infrastructure face à une demande croissante de données.
FONDAMENTAUX
2. Comprendre le Caching : Pourquoi et Où ?
Le principe du caching est simple : si une donnée est coûteuse à obtenir et qu’elle est demandée fréquemment sans changer souvent, stockons-la temporairement dans un endroit plus rapide. Cela permet de servir les requêtes ultérieures beaucoup plus rapidement. Mais où exactement placer ce cache ? Le caching peut être implémenté à plusieurs niveaux de votre architecture.
Les Différents Niveaux de Caching
Pour une API, le caching peut s’appliquer à diverses couches, chacune offrant des avantages spécifiques :
1. Cache Côté Client (Navigateur/Application Mobile) : Le plus proche de l’utilisateur. Les navigateurs web mettent en cache les ressources statiques (images, CSS, JS) via les en-têtes HTTP (Cache-Control, Expires, ETag). Pour les APIs, cela peut concerner des données utilisateur ou des préférences stockées localement.
2. Cache CDN (Content Delivery Network) : Pour les ressources statiques ou les réponses API complètes qui sont les mêmes pour tous les utilisateurs. Les CDN distribuent le contenu sur des serveurs Edge à travers le monde, réduisant la latence en servant le contenu depuis un emplacement géographiquement proche de l’utilisateur. Des services comme Cloudflare ou Akamai sont des exemples majeurs.
3. Cache de Proxy Inverse (Gateway API) : Des serveurs comme Nginx ou Varnish peuvent être configurés pour mettre en cache les réponses des APIs avant même qu’elles n’atteignent votre serveur d’application. C’est efficace pour des endpoints qui reçoivent un trafic élevé et dont les données ne changent pas fréquemment.
4. Cache Côté Serveur (Application/Distribué) : C’est le cœur de notre discussion. Il s’agit de systèmes de cache dédiés (comme Redis ou Memcached) qui stockent les données en mémoire, accessibles directement par votre application backend. Ce niveau est crucial pour les données dynamiques et spécifiques aux utilisateurs.
5. Cache de Base de Données : Certaines bases de données intègrent des mécanismes de cache (cache de requêtes, vues matérialisées) pour accélérer l’accès aux données. Bien que utile, s’appuyer uniquement sur ce niveau peut ne pas suffire pour des APIs à fort trafic.
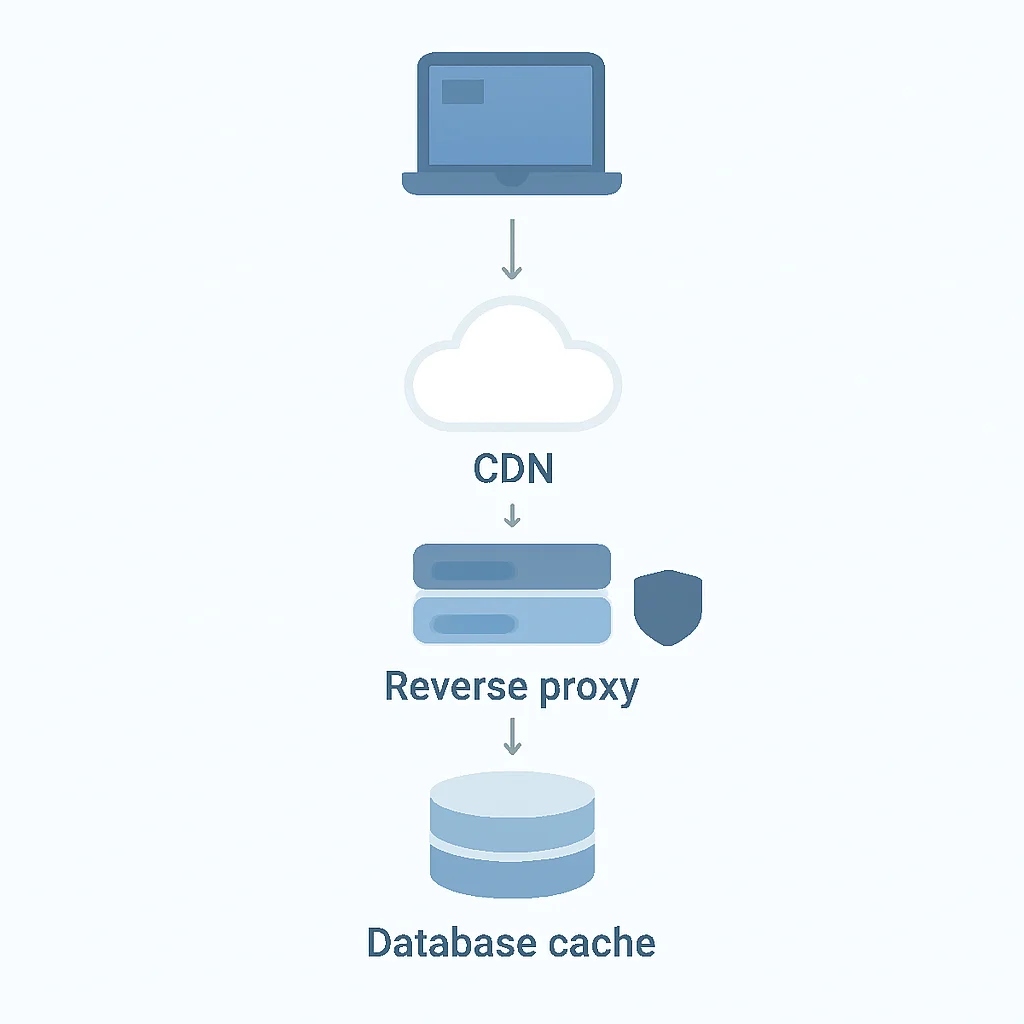
Chaque niveau de cache a son rôle. Une stratégie de caching efficace implique souvent une combinaison de ces niveaux, en fonction de la nature des données et des exigences de performance.
POINT CLÉ
Le caching peut être implémenté à plusieurs niveaux (client, CDN, proxy inverse, application, base de données) pour optimiser la performance à différentes étapes du chemin de la requête. Le cache applicatif (serveur) est essentiel pour les données dynamiques.
STRATÉGIES
3. Les Stratégies de Caching Courantes
Pour une API backend, la mise en cache des données dynamiques est primordiale. Il existe plusieurs patterns d’implémentation, chacun avec ses avantages et ses scénarios d’utilisation privilégiés.
Cache-Aside (Lazy Loading)
C’est la stratégie la plus répandue et la plus flexible. L’application est responsable de la gestion du cache. Lorsqu’elle a besoin de données :
- Elle vérifie d’abord si les données sont présentes dans le cache.
- Si oui (cache hit), elle les récupère directement du cache.
- Si non (cache miss), elle récupère les données de la source de vérité (généralement la base de données).
- Après avoir récupéré les données de la base de données, elle les stocke dans le cache pour les requêtes futures, avec une durée de vie (TTL) si nécessaire.
Avantages : Simplicité d’implémentation, le cache ne contient que les données réellement demandées, évitant le stockage de données inutiles. L’application garde le contrôle total.
Inconvénients : La première requête pour une donnée non cachée sera lente (cache miss). Peut entraîner des données périmées si l’invalidation n’est pas gérée correctement.
Read-Through
Avec cette stratégie, le cache agit comme un proxy pour la base de données. L’application ne communique qu’avec le cache. Si le cache ne trouve pas les données, il est responsable de les récupérer de la base de données, de les stocker, puis de les retourner à l’application.
Avantages : Simplifie le code de l’application car elle n’a pas à gérer la logique de récupération de la base de données en cas de cache miss.
Inconvénients : Nécessite un cache plus « intelligent » capable d’interagir avec la base de données. Peut être plus complexe à configurer.
Write-Through
Lorsqu’une application écrit des données, elle les écrit d’abord dans le cache, puis le cache écrit ces données dans la base de données de manière synchrone. Cela garantit que le cache et la base de données sont toujours cohérents.
Avantages : Forte cohérence entre le cache et la base de données. Les lectures ultérieures sont rapides car les données sont déjà dans le cache.
Inconvénients : Les écritures sont plus lentes car elles doivent attendre que les données soient écrites dans le cache ET dans la base de données.
Write-Back (Write-Behind)
L’application écrit les données dans le cache, et le cache confirme immédiatement l’écriture à l’application. Le cache écrit ensuite les données dans la base de données de manière asynchrone, généralement en arrière-plan ou par lots.
Avantages : Écritures très rapides pour l’application, améliorant la réactivité. Permet de gérer des pics de trafic d’écriture.
Inconvénients : Risque de perte de données en cas de panne du cache avant que les données ne soient persistées en base. Nécessite une gestion complexe de la cohérence et de la tolérance aux pannes.
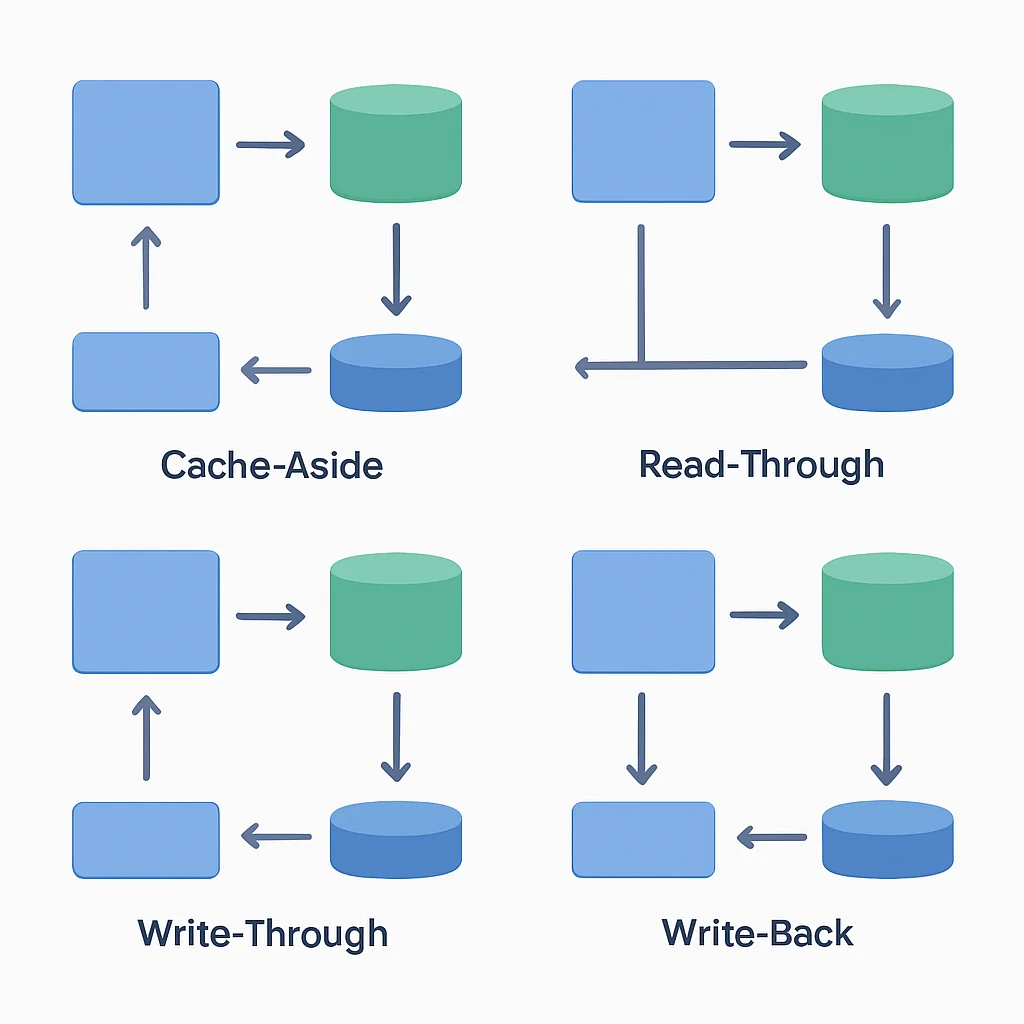
POINT CLÉ
Le pattern Cache-Aside est le plus couramment utilisé en backend pour sa flexibilité et sa simplicité, bien qu’il nécessite une gestion explicite de l’invalidation par l’application.
TECHNOLOGIES
4. Outils de Caching Distribué : Redis vs Memcached
Pour implémenter un cache côté serveur distribué, deux solutions dominent le marché en 2026 : Redis et Memcached. Bien qu’ils partagent le même objectif d’accélération des applications, leurs architectures et fonctionnalités diffèrent considérablement.
Redis (Remote Dictionary Server)
Redis est bien plus qu’un simple cache ; c’est un magasin de données en mémoire, open-source, qui peut être utilisé comme base de données, cache et broker de messages. Il est réputé pour sa vitesse et sa polyvalence.
Fonctionnalités Clés de Redis
Types de données riches — Supporte les chaînes de caractères, les hachages (hashes), les listes, les ensembles (sets), les ensembles triés (sorted sets), les flux (streams), les bitmaps, et les HyperLogLogs.
Persistance — Peut persister les données sur disque (RDB snapshots ou AOF log) pour éviter la perte de données en cas de redémarrage.
Haute disponibilité et Scalabilité — Offre la réplication Maître-Esclave (Master-Replica) et le clustering pour la haute disponibilité et la scalabilité horizontale.
Pub/Sub — Un système de messagerie publish/subscribe intégré, idéal pour l’invalidation de cache en temps réel ou la communication entre microservices.
Transactions — Supporte les transactions atomiques.
Cas d’utilisation typiques de Redis : Caching d’objets ou de pages complètes, gestion de sessions utilisateur, tableaux de classement en temps réel, compteurs, files d’attente de messages (Pub/Sub), géolocalisation.
Memcached
Memcached est un système de cache d’objets en mémoire distribué, simple et performant. Il est conçu pour être une solution de cache clé-valeur rapide et légère.
Fonctionnalités Clés de Memcached
Simplicité — Interface clé-valeur très simple, uniquement des chaînes de caractères comme valeurs.
Purement en mémoire — Ne propose pas de persistance des données. Les données sont perdues en cas de redémarrage du serveur.
Multi-threading — Utilise plusieurs threads pour gérer les connexions client, ce qui peut être avantageux sur des serveurs multi-cœurs.
Scalabilité horizontale — Facile à scaler en ajoutant simplement plus de serveurs Memcached, la logique de distribution étant gérée côté client.
Cas d’utilisation typiques de Memcached : Caching de résultats de requêtes SQL, objets sérialisés, fragments de pages HTML, données utilisateur non critiques.
Comparaison Redis vs Memcached
Le choix entre Redis et Memcached dépendra des besoins spécifiques de votre application. Voici un tableau comparatif pour vous aider à décider :

En résumé, Redis est le choix privilégié pour la plupart des applications modernes nécessitant un cache riche en fonctionnalités, une persistance des données et des capacités de messagerie. Memcached reste une excellente option pour des besoins de caching très simples où la vitesse brute et la faible surcharge sont prioritaires, sans besoin de persistance ni de types de données complexes.
POINT CLÉ
Choisissez Redis pour ses fonctionnalités avancées (types de données, persistance, Pub/Sub) et Memcached pour sa simplicité et sa vitesse brute dans les cas de caching clé-valeur basiques.
DÉFIS & SOLUTIONS
5. Les Défis du Caching : Gestion de l’Invalidation et Cohérence des Données
L’un des plus grands défis du caching est de s’assurer que les données servies par le cache sont toujours fraîches et cohérentes avec la source de vérité (la base de données). Une mauvaise gestion de l’invalidation peut entraîner la présentation de données périmées aux utilisateurs, ce qui est souvent pire que l’absence de cache.
Stratégies d’Invalidation du Cache
1. Expiration basée sur le temps (TTL – Time To Live) : La méthode la plus simple. Chaque élément mis en cache se voit attribuer une durée de vie. Après cette période, l’élément est automatiquement supprimé du cache.
Avantages : Facile à implémenter.
Inconvénients : Peut servir des données périmées jusqu’à l’expiration. Difficile de choisir un TTL optimal pour toutes les données.
2. Invalidation basée sur les événements : Lorsqu’une donnée est modifiée dans la base de données, un événement est déclenché pour invalider l’entrée correspondante dans le cache. Ceci est souvent réalisé via un mécanisme Pub/Sub (comme celui de Redis).
EXPLICATION DU CODE
Cet exemple montre comment un service publie un message sur un canal Redis lorsque des données utilisateur sont mises à jour, et comment un autre service écoute ce canal pour invalider le cache.
// Service de mise à jour utilisateur (Node.js)
const redis = require('ioredis');
const publisher = new redis();
async function updateUser(userId, newData) {
// Mettre à jour la base de données
await db.updateUser(userId, newData);
// Publier un événement d'invalidation
publisher.publish('user_updates', `invalidate:${userId}`);
console.log(`Utilisateur ${userId} mis à jour et événement d'invalidation publié.`);
}
// Service API consommateur (Node.js)
const subscriber = new redis();
const cache = new Map(); // Cache local pour l'exemple
subscriber.subscribe('user_updates', (err, count) => {
if (err) {
console.error("Failed to subscribe: %s", err.message);
} else {
console.log(`Abonné au canal 'user_updates'.`);
}
});
subscriber.on('message', (channel, message) => {
if (channel === 'user_updates' && message.startsWith('invalidate:')) {
const userIdToInvalidate = message.split(':')[1];
if (cache.has(userIdToInvalidate)) {
cache.delete(userIdToInvalidate);
console.log(`Cache pour utilisateur ${userIdToInvalidate} invalidé.`);
}
}
});
// Pour tester:
// updateUser('user123', { name: 'Nouvel Nom' });
Avantages : Cohérence des données quasi-instantanée.
Inconvénients : Plus complexe à implémenter, nécessite un système de messagerie et une gestion robuste des événements.
3. Invalidation basée sur les tags (ou groupes) : Permet d’invalider plusieurs éléments de cache liés en une seule opération. Par exemple, si vous mettez en cache tous les produits d’une catégorie, vous pouvez taguer ces entrées avec category:electronics. Si un produit de cette catégorie est mis à jour, vous invalidez toutes les entrées avec ce tag.
Avantages : Gestion granulaire de l’invalidation pour des groupes de données.
Inconvénients : Nécessite un support de tagging dans votre solution de cache (Redis peut le faire avec des sets ou des hachages) et une gestion rigoureuse des tags.
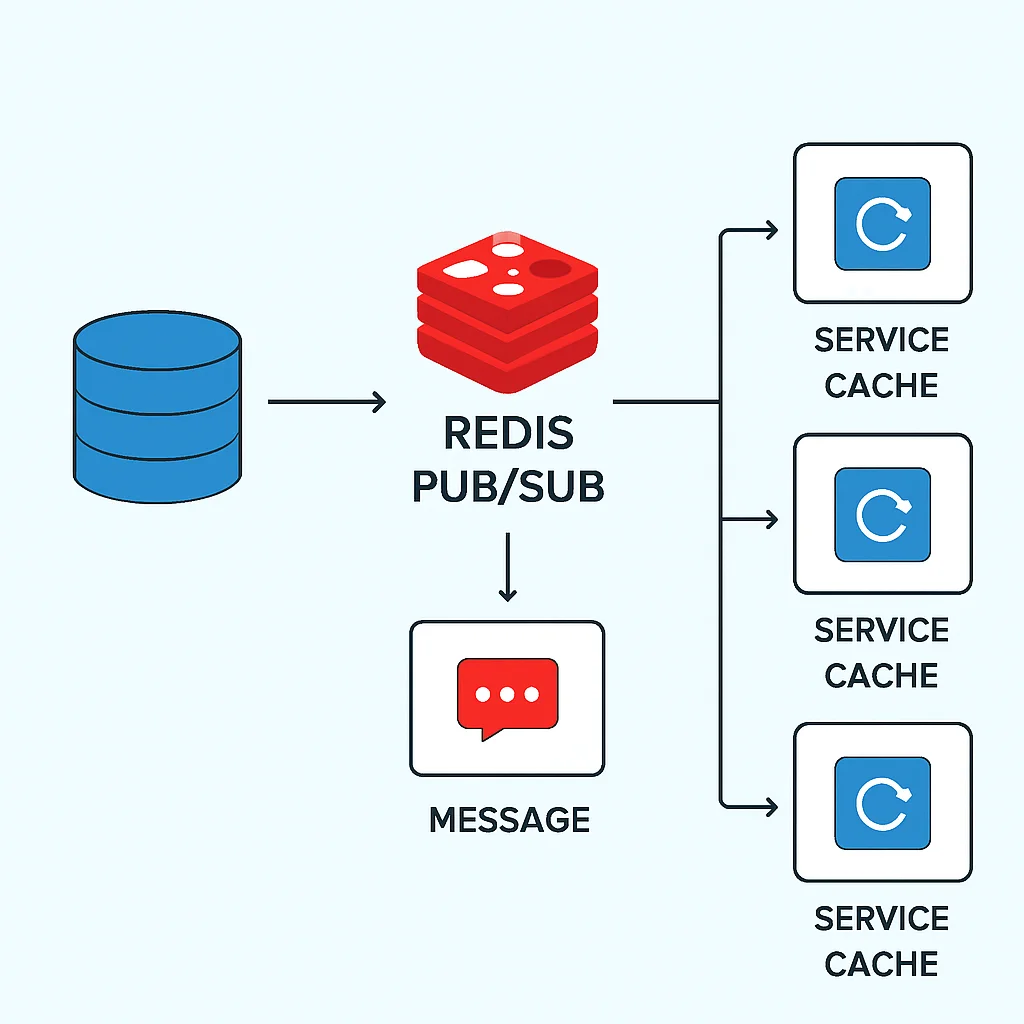
Problèmes Communs et Leurs Solutions
POINT CLÉ
Une gestion proactive de l’invalidation, combinant TTL et stratégies basées sur les événements, est cruciale pour maintenir la cohérence des données. Des techniques comme les verrous distribués aident à prévenir le « cache stampede ».
APPLICATION PRATIQUE
6. Application Pratique : Implémenter le Caching avec Redis
Voyons comment implémenter concrètement le pattern Cache-Aside avec Redis dans une API Node.js. Nous allons simuler une API qui récupère des informations utilisateur depuis une base de données (ici, une fonction asynchrone qui simule un délai).
Prérequis
- Node.js et npm installés.
- Un serveur Redis en cours d’exécution (localement ou sur un service cloud).
- Installer la bibliothèque Redis pour Node.js :
npm install ioredis express
Étape 1 : Initialisation de Redis et de l’Application Express
EXPLICATION DU CODE
Ce code initialise un client Redis et une application Express. Il simule également une base de données avec une fonction fetchUserFromDB qui introduit un délai pour simuler une latence.
// app.js
const express = require('express');
const Redis = require('ioredis');
const app = express();
const port = 3000;
// Connecter à Redis
const redisClient = new Redis({
host: 'localhost', // Ou l'adresse de votre serveur Redis
port: 6379,
});
redisClient.on('connect', () => console.log('Connecté à Redis !'));
redisClient.on('error', (err) => console.error('Erreur Redis :', err));
// Simuler une base de données
const users = {
'1': { id: '1', name: 'Alice Dupont', email: '[email protected]', role: 'admin' },
'2': { id: '2', name: 'Bob Martin', email: '[email protected]', role: 'user' },
'3': { id: '3', name: 'Charlie Leblanc', email: '[email protected]', role: 'guest' },
};
async function fetchUserFromDB(userId) {
console.log(`Récupération de l'utilisateur ${userId} depuis la base de données...`);
return new Promise(resolve => {
setTimeout(() => {
resolve(users[userId]);
}, 1000); // Simuler une latence de 1 seconde
});
}
app.listen(port, () => {
console.log(`API en cours d'exécution sur http://localhost:${port}`);
});
Étape 2 : Implémentation du Caching (Cache-Aside)
EXPLICATION DU CODE
Ce bloc ajoute un endpoint /users/:id qui implémente le pattern Cache-Aside. Il vérifie d’abord le cache Redis. Si la donnée n’est pas trouvée, elle est récupérée de la « DB » et stockée dans Redis avec un TTL de 60 secondes.
// app.js (suite)
app.get('/users/:id', async (req, res) => {
const userId = req.params.id;
const cacheKey = `user:${userId}`;
const CACHE_TTL = 60; // Durée de vie du cache en secondes
try {
// 1. Essayer de récupérer de Redis
let cachedUser = await redisClient.get(cacheKey);
if (cachedUser) {
console.log(`Cache hit pour l'utilisateur ${userId}`);
return res.json(JSON.parse(cachedUser));
}
// 2. Si pas dans le cache, récupérer de la DB
console.log(`Cache miss pour l'utilisateur ${userId}. Récupération de la DB...`);
const user = await fetchUserFromDB(userId);
if (!user) {
return res.status(404).json({ message: 'Utilisateur non trouvé' });
}
// 3. Stocker dans Redis pour les futures requêtes
await redisClient.setex(cacheKey, CACHE_TTL, JSON.stringify(user));
console.log(`Utilisateur ${userId} mis en cache avec un TTL de ${CACHE_TTL}s`);
res.json(user);
} catch (error) {
console.error('Erreur lors de la récupération de l\'utilisateur :', error);
res.status(500).json({ message: 'Erreur serveur interne' });
}
});
Étape 3 : Ajout d’un Endpoint d’Invalidation
EXPLICATION DU CODE
Ce nouveau endpoint /users/:id/invalidate permet d’invalider manuellement une entrée de cache pour un utilisateur spécifique. Dans une application réelle, cette invalidation serait déclenchée après une modification de l’utilisateur en base de données.
// app.js (suite)
app.post('/users/:id/invalidate', async (req, res) => {
const userId = req.params.id;
const cacheKey = `user:${userId}`;
try {
const deletedCount = await redisClient.del(cacheKey);
if (deletedCount > 0) {
console.log(`Cache pour l'utilisateur ${userId} invalidé.`);
res.json({ message: `Cache pour l'utilisateur ${userId} invalidé.` });
} else {
console.log(`Aucune entrée de cache trouvée pour l'utilisateur ${userId}.`);
res.status(404).json({ message: `Aucune entrée de cache trouvée pour l'utilisateur ${userId}.` });
}
} catch (error) {
console.error('Erreur lors de l\'invalidation du cache :', error);
res.status(500).json({ message: 'Erreur serveur interne' });
}
});
Comment tester ?
- Démarrez votre serveur Redis.
- Exécutez
node app.js. - Première requête :
curl http://localhost:3000/users/1. Vous verrez « Récupération de l’utilisateur 1 depuis la base de données… » et un délai de 1 seconde. - Requêtes suivantes (dans les 60 secondes) :
curl http://localhost:3000/users/1. Vous verrez « Cache hit pour l’utilisateur 1 » et la réponse sera quasi-instantanée. - Invalidez le cache :
curl -X POST http://localhost:3000/users/1/invalidate. - Refaites une requête :
curl http://localhost:3000/users/1. Le cache sera manquant et la donnée sera récupérée de la DB à nouveau.
POINT CLÉ
L’implémentation du Cache-Aside avec Redis est relativement simple et offre un gain de performance immédiat pour les données fréquemment consultées. La clé est une gestion précise du TTL et de l’invalidation.
CAS D’USAGE
7. Cas d’Usage Réels du Caching
Le caching n’est pas une solution unique, mais une stratégie versatile applicable à de nombreux scénarios pour améliorer la performance et la scalabilité.
Cas d’Usage 1 : Pages Produits E-commerce
Les informations sur les produits (description, prix, images) sont fréquemment consultées mais changent rarement. Mettre en cache ces données réduit la charge sur la base de données produit, surtout lors de pics de trafic (ex: Black Friday). Un TTL de quelques heures ou une invalidation événementielle lors de la mise à jour d’un produit sont de bonnes approches.
Cas d’Usage 2 : Fils d’Actualité des Réseaux Sociaux
Un fil d’actualité personnalisé pour chaque utilisateur peut être coûteux à générer en temps réel (agrégation de posts, likes, commentaires). Cacher le fil pré-généré pour un utilisateur pendant quelques minutes permet une récupération quasi-instantanée, avec une invalidation lors de la publication d’un nouveau contenu par les personnes suivies.
Cas d’Usage 3 : Tableaux de Bord et Statistiques en Temps Réel
Les agrégations de données complexes pour des tableaux de bord analytiques peuvent prendre du temps à calculer. Mettre en cache les résultats de ces agrégations pour une durée limitée (par exemple, 5-10 minutes) permet de servir des données « quasi-temps réel » sans surcharger les systèmes analytiques sous-jacents. Redis est excellent pour cela avec ses structures de données.
Cas d’Usage 4 : Authentification et Sessions Utilisateur
Les données de session utilisateur (jetons d’authentification, préférences) sont fréquemment consultées. Les stocker dans un cache distribué comme Redis permet une gestion rapide et scalable des sessions à travers plusieurs instances de votre application, réduisant la charge sur la base de données principale.
POINT CLÉ
Le caching est applicable à une multitude de scénarios backend, des pages produits aux fils d’actualité en passant par les sessions utilisateur, offrant des gains de performance significatifs et une meilleure résilience de l’infrastructure.
Foire Aux Questions (FAQ)
Q. Qu’est-ce que le caching API et pourquoi est-il essentiel en 2026 ?
Le caching API est la technique de stockage temporaire des réponses API fréquemment demandées pour les servir plus rapidement. En 2026, il est essentiel pour répondre aux attentes des utilisateurs en matière de vitesse, réduire la charge sur les bases de données et les serveurs, et soutenir la scalabilité des architectures modernes.
Q. Quelle est la différence principale entre Redis et Memcached ?
Redis est un magasin de données en mémoire polyvalent supportant de nombreux types de données, la persistance, la réplication et un système Pub/Sub. Memcached est un cache clé-valeur plus simple, purement en mémoire, sans persistance, offrant une grande vitesse pour des cas d’utilisation basiques.
Q. Comment éviter les données périmées dans mon cache ?
Pour éviter les données périmées, utilisez une combinaison de TTL (Time To Live) pour les données moins critiques et des stratégies d’invalidation basées sur les événements (par exemple, via Redis Pub/Sub) pour les données qui changent fréquemment et nécessitent une fraîcheur maximale.
Q. Qu’est-ce que le « cache stampede » et comment le prévenir ?
Le « cache stampede » se produit lorsque de nombreuses requêtes tentent simultanément de recalculer ou de récupérer une donnée de la base de données après l’expiration du cache. On le prévient en utilisant des verrous distribués (par exemple, avec SET NX EX de Redis) pour s’assurer qu’une seule requête régénère le cache.
Q. Le caching peut-il introduire de nouveaux problèmes de sécurité ?
Oui, le caching peut introduire des problèmes de sécurité s’il n’est pas géré correctement. Par exemple, des données sensibles pourraient être exposées si le cache n’est pas sécurisé ou si des données utilisateur sont accidentellement mises en cache et servies à d’autres utilisateurs. Il est crucial de s’assurer que les données mises en cache sont appropriées et que le système de cache est protégé.
Merci de votre lecture !
L’optimisation des APIs par le caching est une compétence cruciale en 2026. En maîtrisant les stratégies et les outils comme Redis, vous construirez des systèmes plus rapides, plus résilients et plus économiques.
Des questions ? Laissez un commentaire !