

RÉSUMÉ
[IA & ML] Fine-Tuner un LLM en 2026 : Guide pratique pour des modèles spécialisés
Apprenez à fine-tuner des Large Language Models (LLM) pour des tâches spécifiques et performantes.
Keywords: LLM, fine-tuning, modèles spécialisés
TABLE DES MATIÈRES
1. Contexte : L’Ère des LLM Spécialisés en 2026
2. Comprendre le Fine-Tuning de LLM
3. Préparation des Données : Le Carburant du Fine-Tuning
4. Choix du Modèle de Base et des Outils
5. Stratégies et Hyperparamètres pour un Fine-Tuning Efficace
6. Évaluation et Optimisation des Modèles Fine-Tunés
7. Défis du Fine-Tuning et Leurs Solutions
8. Guide Pratique : Fine-Tuner un LLM avec Hugging Face et PEFT
9. Conclusion : L’Avenir du Fine-Tuning en 2026
10. Questions Fréquentes
INTRODUCTION
1. Contexte : L’Ère des LLM Spécialisés en 2026
En 2026, l’intelligence artificielle a franchi de nouvelles étapes, et les Large Language Models (LLM) sont au cœur de cette révolution. Des modèles comme GPT-4, Llama 3 ou Mistral ont démontré des capacités impressionnantes pour une multitude de tâches génériques. Cependant, pour des applications spécifiques nécessitant une compréhension nuancée, une terminologie sectorielle ou des comportements précis, ces modèles généralistes atteignent leurs limites. C’est là qu’intervient le fine-tuning d’un LLM : une technique essentielle pour adapter ces géants du langage à des besoins ultra-spécialisés, transformant un modèle polyvalent en un expert thématique.
Le fine-tuning permet aux entreprises et aux développeurs de créer des modèles spécialisés qui surpassent les performances des modèles de base sur des tâches ciblées, tout en réduisant considérablement les coûts et le temps de développement par rapport à un entraînement à partir de zéro. Par exemple, un LLM fine-tuné sur des données juridiques peut devenir un assistant juridique inestimable, capable de rédiger des contrats ou d’analyser des documents avec une précision que même les modèles les plus avancés ne peuvent atteindre sans cette spécialisation. Ce guide pratique explorera les étapes, les outils et les meilleures pratiques pour maîtriser le fine-tuning en 2026, vous permettant de débloquer le plein potentiel de l’IA pour vos projets.
POINT CLÉ
Le fine-tuning transforme un LLM généraliste en un modèle expert pour des tâches spécifiques, offrant une performance et une pertinence accrues tout en optimisant les ressources.
ANALYSE DÉTAILLÉE
2. Comprendre le Fine-Tuning de LLM
Le fine-tuning, ou « ajustement fin », est un processus d’entraînement secondaire qui adapte un modèle de langage pré-entraîné (le modèle de base) à une tâche ou un domaine spécifique, en utilisant un jeu de données plus petit et ciblé. Contrairement à l’entraînement initial qui vise une compréhension générale du langage, le fine-tuning affine les poids du modèle pour qu’il excelle dans un contexte particulier.
Pourquoi le Fine-Tuning est-il Indispensable en 2026 ?
Les LLM pré-entraînés sont formidables pour des tâches génériques comme la traduction, la génération de texte créatif ou la réponse à des questions générales. Cependant, ils présentent des lacunes pour les scénarios suivants :
- Connaissances Spécifiques : Les modèles généralistes n’ont pas toujours accès aux informations les plus récentes ou aux connaissances très spécialisées d’un domaine (ex: médecine, finance, droit).
- Style et Ton : Une entreprise peut souhaiter que son IA communique avec un ton spécifique (formel, amical, marketing) ou un style de rédaction propre à sa marque.
- Réduction des Hallucinations : En les exposant à des données factuelles et vérifiées de votre domaine, le fine-tuning peut réduire la tendance des LLM à « halluciner » ou à générer des informations incorrectes.
- Optimisation des Coûts et de la Latence : Un modèle fine-tuné plus petit peut souvent surpasser un modèle plus grand et coûteux sur des tâches spécifiques, permettant des déploiements plus efficaces.
Les Différents Types de Fine-Tuning
Il existe plusieurs approches pour fine-tuner un LLM, chacune avec ses compromis en termes de performance, de coût et de ressources nécessaires :
Approches de Fine-Tuning
1. Full Fine-Tuning — Entraîne tous les poids du modèle de base. Offre la meilleure performance potentielle mais est très coûteux en ressources (GPU, temps) et nécessite un grand jeu de données.
2. Fine-Tuning Efficace en Paramètres (PEFT – Parameter-Efficient Fine-Tuning) — N’entraîne qu’un petit sous-ensemble de paramètres ou ajoute de nouvelles couches légères. Réduit drastiquement les besoins en calcul et en mémoire. Exemples : LoRA (Low-Rank Adaptation) et QLoRA.
3. Prompt-Tuning / Prefix-Tuning — N’entraîne pas les poids du modèle, mais apprend des « prompts » ou « préfixes » spécifiques qui sont ajoutés à l’entrée du modèle. Très léger, mais moins performant que PEFT pour des tâches complexes.
4. Reinforcement Learning from Human Feedback (RLHF) — Une technique avancée qui utilise le feedback humain pour aligner le comportement du LLM avec les préférences humaines, souvent après un fine-tuning supervisé initial. Crucial pour la sécurité et la pertinence.
En 2026, les méthodes PEFT, en particulier LoRA et QLoRA, sont devenues la norme pour la plupart des cas d’usage, offrant un excellent équilibre entre performance et efficacité. Elles permettent de fine-tuner des modèles de plusieurs milliards de paramètres sur du matériel accessible (GPU de niveau consommateur) et avec des jeux de données plus modestes.
DONNÉES & PRÉPARATION
3. Préparation des Données : Le Carburant du Fine-Tuning
La qualité des données d’entraînement est le facteur le plus critique pour le succès du fine-tuning. Un modèle ne peut être meilleur que les données sur lesquelles il est entraîné. En 2026, l’accent est mis sur des datasets propres, pertinents et bien structurés.
Collecte et Curation des Données
La première étape consiste à collecter des données représentatives de la tâche ou du domaine cible. Pour un chatbot de support client, cela pourrait être des transcriptions de conversations passées ; pour un générateur de code, des exemples de code commenté. Les sources peuvent inclure :
- Données Internes de l’Entreprise : Documents propriétaires, bases de connaissances, historiques de conversations, rapports techniques.
- Données Publiques Spécialisées : Corpus scientifiques (PubMed), datasets juridiques (Caselaw Access Project), forums techniques (Stack Overflow).
- Données Synthétiques : Générées par d’autres LLM pour augmenter la taille du dataset, sous supervision humaine rigoureuse pour éviter la propagation de biais.
Une fois collectées, les données doivent être soigneusement curées : suppression des doublons, gestion des informations sensibles (PII – Personally Identifiable Information), correction des erreurs grammaticales ou factuelles, et filtrage des contenus toxiques ou biaisés.
Formatage des Données pour le Fine-Tuning Supervisé
Pour le fine-tuning supervisé, les données sont généralement formatées en paires « instruction-réponse » ou « prompt-complétion ». Cela apprend au modèle à générer une sortie spécifique en réponse à une entrée donnée. Un format courant est le format JSON Lines, où chaque ligne est un objet JSON représentant une interaction.
EXPLICATION DU CODE
Cet exemple montre un format JSON Lines typique pour le fine-tuning d’un LLM. Chaque objet contient un champ instruction (la requête de l’utilisateur ou la tâche) et un champ output (la réponse attendue du modèle). Ce format est idéal pour entraîner le modèle à suivre des instructions spécifiques et à générer des réponses pertinentes.
[
{
"instruction": "Expliquez l'importance du fine-tuning pour les LLM en 2026.",
"output": "En 2026, le fine-tuning est crucial pour spécialiser les LLM génériques. Il permet d'adapter ces modèles à des tâches spécifiques, d'améliorer leur précision sur des domaines précis, de réduire les hallucinations et d'optimiser les coûts opérationnels en utilisant des modèles plus petits et ciblés."
},
{
"instruction": "Donnez un exemple de cas d'utilisation pour un LLM fine-tuné dans le secteur financier.",
"output": "Un LLM fine-tuné dans le secteur financier pourrait analyser des rapports de marché, détecter des anomalies dans les transactions pour la fraude, ou générer des résumés de bilans annuels avec une terminologie économique précise et une compréhension contextuelle approfondie."
},
{
"instruction": "Quel est l'avantage principal de LoRA par rapport au full fine-tuning ?",
"output": "L'avantage principal de LoRA (Low-Rank Adaptation) est son efficacité en termes de paramètres. Il ne fine-tune qu'un petit nombre de matrices de faible rang, réduisant drastiquement les besoins en calcul et en mémoire GPU, tout en atteignant des performances comparables au full fine-tuning sur de nombreuses tâches."
}
]
Pour des tâches de résumé ou de traduction, le format pourrait être simplement {"text": "Input document", "summary": "Generated summary"} ou {"source_lang": "text in source language", "target_lang": "text in target language"}. L’important est la cohérence et la pertinence du format par rapport à la tâche.
POINT CLÉ
Un jeu de données de fine-tuning de haute qualité, pertinent et bien structuré est le pilier d’un modèle spécialisé performant. Concentrez-vous sur la curation, le nettoyage et le formatage correct des données.
TECHNOLOGIE & OUTILS
4. Choix du Modèle de Base et des Outils
Le choix du modèle de base est une décision stratégique qui impacte directement la performance et les coûts du fine-tuning. En 2026, l’écosystème des LLM est riche, avec une concurrence féroce entre modèles open-source et propriétaires.
Sélection du Modèle de Base
Les critères de sélection incluent :
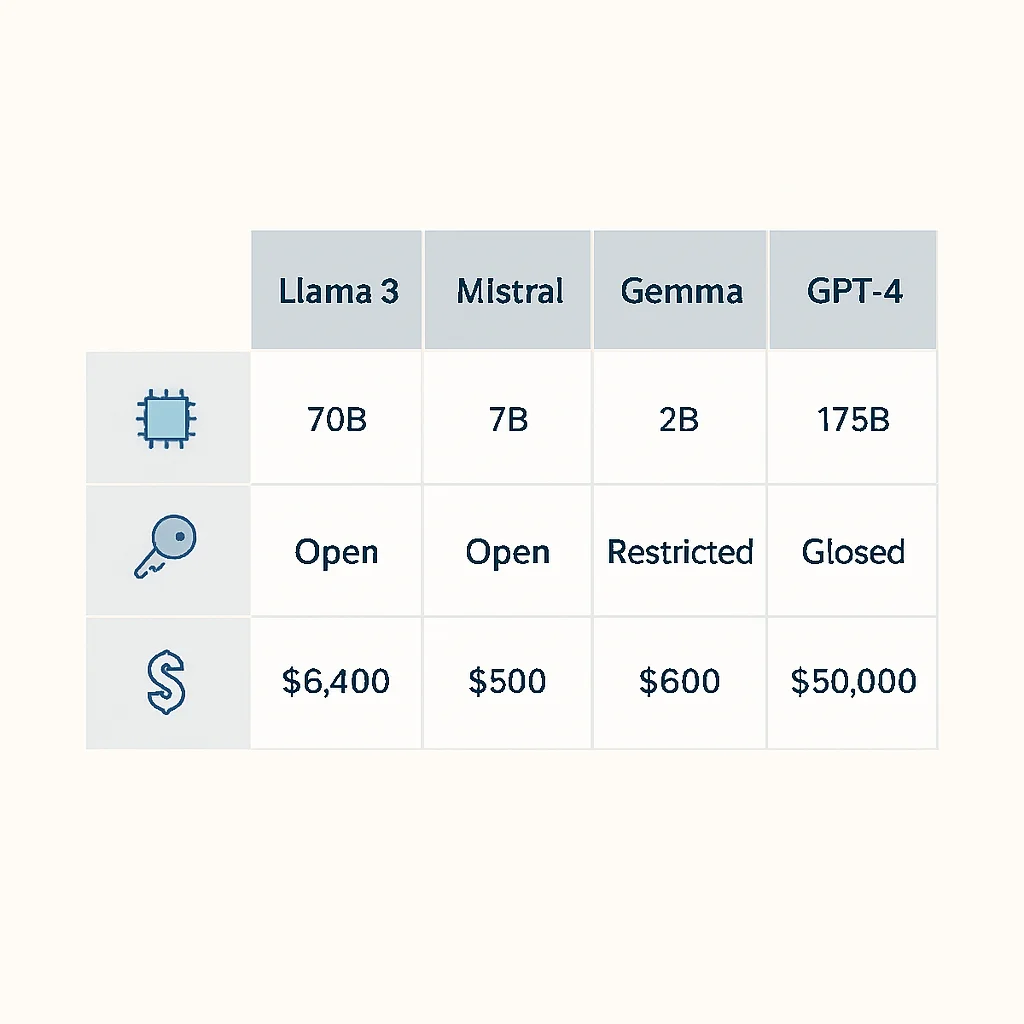
- Taille et Capacités : Un modèle plus grand (ex: 70 milliards de paramètres) aura généralement de meilleures capacités de raisonnement, mais sera plus coûteux à fine-tuner. Des modèles plus petits (ex: 7B, 13B) peuvent être suffisants avec un bon fine-tuning.
- Licence : Les modèles open-source (Llama 3, Mistral, Gemma) offrent une flexibilité et un contrôle total, tandis que les modèles propriétaires (GPT-4 d’OpenAI, Claude d’Anthropic) peuvent offrir des performances brutes supérieures mais avec des coûts d’API et des restrictions d’utilisation.
- Architecture : Certains modèles sont optimisés pour des tâches spécifiques (ex: génération de code).
- Disponibilité des Ressources : La communauté autour du modèle, la documentation, les exemples de fine-tuning existants.
7.8
/ 10
Score moyen de performance des LLM open-source fine-tunés par rapport aux modèles propriétaires pour des tâches spécialisées.
En 2026, des modèles comme Llama 3 (Meta), Mistral (Mistral AI) et Gemma (Google) sont des choix populaires pour le fine-tuning, grâce à leurs performances compétitives et leur accessibilité.
Outils et Frameworks Essentiels
Le paysage des outils d’IA évolue rapidement. Voici les incontournables pour le fine-tuning en 2026 :
- Hugging Face Transformers : La bibliothèque de facto pour travailler avec les LLM. Elle fournit des API unifiées pour charger, entraîner et utiliser des milliers de modèles pré-entraînés.
- Hugging Face PEFT (Parameter-Efficient Fine-Tuning) : Une bibliothèque dédiée aux méthodes de fine-tuning efficaces comme LoRA, QLoRA, etc. Elle s’intègre parfaitement avec Transformers.
- Hugging Face TRL (Transformer Reinforcement Learning) : Pour les méthodes de fine-tuning basées sur le renforcement (RLHF), essentielles pour l’alignement des modèles.
- PyTorch / TensorFlow : Les frameworks d’apprentissage profond sous-jacents. Bien que souvent abstraits par Hugging Face, une connaissance de base est utile.
- Weights & Biases (W&B) / MLflow : Pour le suivi des expériences, la gestion des hyperparamètres et la visualisation des métriques d’entraînement.
POINT CLÉ
Choisissez un modèle de base open-source comme Llama 3 ou Mistral pour la flexibilité et l’efficacité, et utilisez l’écosystème Hugging Face (Transformers, PEFT) pour simplifier le processus de fine-tuning.
STRATÉGIES
5. Stratégies et Hyperparamètres pour un Fine-Tuning Efficace
Le fine-tuning n’est pas qu’une question de code ; c’est aussi un art qui nécessite une compréhension des hyperparamètres et des stratégies d’entraînement pour obtenir les meilleurs résultats.
Hyperparamètres Clés
Les hyperparamètres doivent être soigneusement ajustés pour chaque tâche et chaque modèle. Voici les plus importants :
- Taux d’Apprentissage (Learning Rate) : C’est l’un des hyperparamètres les plus critiques. Pour le fine-tuning, un taux d’apprentissage plus faible (ex:
1e-5à5e-5) est généralement préféré pour ne pas « oublier » les connaissances pré-existantes du modèle de base. - Taille du Batch (Batch Size) : Le nombre d’exemples traités avant la mise à jour des poids. Une taille de batch plus grande peut stabiliser l’entraînement mais nécessite plus de mémoire GPU. Pour les LLM, des tailles de batch de
4à32sont courantes. - Nombre d’Époques (Number of Epochs) : Le nombre de fois que le modèle parcourt l’ensemble du jeu de données d’entraînement. Pour le fine-tuning, 1 à 5 époques suffisent souvent pour éviter le surapprentissage.
- Longueur Maximale de Séquence (Max Sequence Length) : La longueur maximale des entrées/sorties du modèle. Elle doit être adaptée à la taille moyenne de vos données et aux capacités du modèle.
- Paramètres LoRA (si utilisé) :
r(rank) : Le rang des matrices de mise à jour. Des valeurs typiques sont8,16,32. Unrplus élevé capture plus de détails mais augmente légèrement la complexité.lora_alpha: Un facteur de mise à l’échelle pour les matrices LoRA. Souvent défini comme2 * r.lora_dropout: Taux de dropout appliqué aux couches LoRA pour éviter le surapprentissage. Typiquement0.05ou0.1.
Stratégies d’Entraînement Avancées
Pour maximiser l’efficacité et la performance, considérez les stratégies suivantes :
- Warmup et Décroissance du Taux d’Apprentissage : Commencer avec un très petit taux d’apprentissage et l’augmenter progressivement (warmup), puis le faire décroître pour affiner l’entraînement. C’est crucial pour la stabilité.
- Quantification (QLoRA) : Entraîner des modèles 4-bit pour réduire drastiquement la consommation de mémoire GPU, permettant de fine-tuner des modèles de grande taille sur du matériel standard.
- Gradient Accumulation : Simule une plus grande taille de batch en accumulant les gradients sur plusieurs mini-batches avant de mettre à jour les poids. Utile lorsque la mémoire GPU est limitée.
- Early Stopping : Arrêter l’entraînement si la performance sur un jeu de validation ne s’améliore plus après un certain nombre d’époques, pour éviter le surapprentissage.
POINT CLÉ
Un taux d’apprentissage faible, une taille de batch appropriée et l’utilisation de techniques PEFT comme LoRA avec des paramètres bien choisis sont essentiels pour un fine-tuning efficace et éviter le surapprentissage.
ÉVALUATION
6. Évaluation et Optimisation des Modèles Fine-Tunés
Une fois le fine-tuning terminé, il est crucial d’évaluer la performance du modèle pour s’assurer qu’il répond aux objectifs fixés. L’évaluation ne se limite pas aux métriques techniques ; elle doit aussi inclure une dimension qualitative.
Métriques d’Évaluation
Les métriques varient en fonction de la tâche :
- Perplexité : Une mesure de la « surprise » du modèle face à une séquence de mots. Une perplexité plus faible indique une meilleure modélisation du langage. Utile pour les tâches de génération de texte.
- ROUGE / BLEU : Pour les tâches de résumé et de traduction. Mesurent le chevauchement entre le texte généré et le texte de référence.
- F1-Score / Précision / Rappel : Pour les tâches de classification ou d’extraction d’informations (NER – Named Entity Recognition).
- Exact Match / Exactitude : Pour les tâches de réponse à des questions où une réponse unique et précise est attendue.
- Évaluation Humaine : Indispensable. Des évaluateurs humains jugent la pertinence, la cohérence, la fluidité, la facticité et le ton des réponses du modèle. C’est souvent la « vérité terrain » ultime.
« En 2026, l’évaluation humaine reste le gold standard pour valider la qualité et l’alignement des LLM fine-tunés, complétant parfaitement les métriques automatiques. »
Techniques d’Optimisation
Si les résultats ne sont pas satisfaisants, plusieurs pistes d’optimisation peuvent être explorées :
- Amélioration du Dataset : Réviser les données d’entraînement. Ajouter plus d’exemples diversifiés, corriger les erreurs, ou affiner la qualité des étiquettes. Un nettoyage plus rigoureux des données est souvent la solution la plus efficace.
- Ajustement des Hyperparamètres : Expérimenter avec différents taux d’apprentissage, tailles de batch, nombres d’époques, ou paramètres LoRA. Utiliser des outils d’optimisation d’hyperparamètres (ex: Optuna, Ray Tune).
- Changement de Modèle de Base : Si le modèle choisi initialement n’atteint pas les performances souhaitées, essayer un modèle de base plus grand ou avec une architecture différente.
- Augmentation des Données : Créer de nouveaux exemples d’entraînement en modifiant légèrement les exemples existants (paraphrase, synonymes) ou en utilisant d’autres LLM pour générer des données synthétiques.
- RLHF (Reinforcement Learning from Human Feedback) : Pour des problèmes d’alignement ou de style, l’intégration du feedback humain via RLHF peut transformer la qualité des réponses générées.
POINT CLÉ
L’évaluation rigoureuse, combinant métriques automatiques et feedback humain, est essentielle. L’optimisation passe souvent par l’amélioration du dataset ou l’ajustement fin des hyperparamètres, et en 2026, le RLHF est une technique de plus en plus pertinente.
DÉFIS & SOLUTIONS
7. Défis du Fine-Tuning et Leurs Solutions
Le fine-tuning, bien que puissant, n’est pas sans défis. En 2026, plusieurs problèmes courants persistent, mais des solutions éprouvées permettent de les surmonter.
PROBLÈME 01
Coût Computationnel Élevé et Exigences en Mémoire GPU
Les LLM modernes ont des milliards de paramètres, rendant le full fine-tuning extrêmement coûteux en ressources GPU (VRAM et puissance de calcul), souvent inabordable pour les petites équipes ou les budgets limités.
SOLUTION — Utilisation de PEFT (LoRA/QLoRA) et Quantification
Les techniques de Fine-Tuning Efficace en Paramètres (PEFT), comme LoRA et QLoRA, sont la réponse. Elles permettent de fine-tuner uniquement un petit sous-ensemble de paramètres (souvent moins de 1% des paramètres totaux) ou d’ajouter de nouvelles couches légères. QLoRA, en particulier, combine LoRA avec la quantification 4-bit, réduisant la consommation de VRAM de 75% à 90% par rapport au full fine-tuning. Cela rend le fine-tuning de modèles de 7B ou 13B possible sur une seule carte GPU de niveau consommateur (ex: NVIDIA RTX 4090 de 24 Go).
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import LoraConfig, get_peft_model, prepare_model_for_kbit_training
# 1. Charger le tokenizer et le modèle de base (quantifié si QLoRA)
model_id = "meta-llama/Llama-2-7b-hf" # Exemple, remplacer par un modèle 2026
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
load_in_4bit=True, # Active la quantification 4-bit pour QLoRA
device_map="auto"
)
# 2. Préparer le modèle pour l'entraînement k-bit (QLoRA)
model = prepare_model_for_kbit_training(model)
# 3. Configurer LoRA
lora_config = LoraConfig(
r=16, # Rang des matrices LoRA
lora_alpha=32, # Facteur d'échelle
lora_dropout=0.05, # Taux de dropout
bias="none",
task_type="CAUSAL_LM",
)
# 4. Appliquer LoRA au modèle
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()
# Exemple de sortie: trainable params: 4,194,304 || all params: 6,738,415,616 || trainable%: 0.06224
PROBLÈME 02
Données d’Entraînement Limitées ou Bruitées
Obtenir un grand jeu de données de haute qualité pour une tâche spécifique est souvent difficile. Des données insuffisantes peuvent mener au surapprentissage, tandis que des données bruitées peuvent entraîner des performances médiocres ou des biais.
SOLUTION — Augmentation de Données, Filtrage et Curration Rigoureuse
La meilleure approche est la combinaison. Commencez par une curation rigoureuse pour nettoyer les données existantes. Utilisez ensuite des techniques d’augmentation de données : paraphrase d’exemples existants, génération de données synthétiques avec un LLM plus puissant (en validant manuellement la qualité), ou traduction inverse. Un filtrage attentif des données avant l’entraînement est également crucial pour éliminer les erreurs et les incohérences.
PROBLÈME 03
Biais, Hallucinations et Manque d’Alignement
Même fine-tuné, un LLM peut toujours générer des informations incorrectes (hallucinations), propager des biais présents dans les données d’entraînement ou ne pas s’aligner avec les valeurs et les objectifs de l’utilisateur.
SOLUTION — Fine-Tuning Supervisé de Qualité et RLHF
Pour réduire les hallucinations, assurez-vous que votre jeu de données de fine-tuning est factuel et vérifié. Pour les biais, diversifiez vos données et utilisez des techniques de débiaisage. Pour l’alignement, le Reinforcement Learning from Human Feedback (RLHF) est la technique la plus avancée en 2026. Il permet d’entraîner le modèle à préférer les réponses qui sont utiles, honnêtes et inoffensives, basées sur des classements humains.
APPLICATION PRATIQUE
8. Guide Pratique : Fine-Tuner un LLM avec Hugging Face et PEFT
Passons à l’action avec un exemple simplifié de fine-tuning d’un LLM en utilisant l’écosystème Hugging Face. Nous allons nous concentrer sur LoRA pour son efficacité.
Étape 1 : Préparer l’Environnement et les Données
1
Installation et Chargement des Données
Assurez-vous d’avoir les bibliothèques nécessaires installées et préparez votre dataset. Pour cet exemple, nous allons simuler un petit dataset.
EXPLICATION DU CODE
Ce code installe les bibliothèques requises et prépare un dataset simple au format Hugging Face Dataset. Nous utilisons un petit jeu de données pour illustrer le processus. En production, vous chargeriez votre propre fichier JSON ou CSV.
!pip install transformers peft accelerate bitsandbytes datasets
from datasets import Dataset
import pandas as pd
# Simuler un petit jeu de données pour l'exemple
data = [
{"instruction": "Quelle est la capitale de la France ?", "output": "La capitale de la France est Paris."},
{"instruction": "Quel est le plus grand océan du monde ?", "output": "Le plus grand océan du monde est l'océan Pacifique."},
{"instruction": "Qui a écrit 'Les Misérables' ?", "output": "Victor Hugo a écrit 'Les Misérables'."}
]
df = pd.DataFrame(data)
dataset = Dataset.from_pandas(df)
# Fonction de formatage pour le fine-tuning
def format_prompt(sample):
return f"### Instruction:\n{sample['instruction']}\n\n### Réponse:\n{sample['output']}"
dataset = dataset.map(lambda x: {"text": format_prompt(x)})
print(dataset[0]["text"])
Étape 2 : Charger le Modèle et le Tokenizer avec QLoRA
2
Configuration du Modèle de Base et LoRA
Nous allons charger un modèle de base (ici Llama-2-7b-hf pour l’exemple, mais vous utiliseriez un modèle de 2026 comme Llama 3 ou Mistral) et le préparer pour le fine-tuning avec QLoRA.
EXPLICATION DU CODE
Cette section charge le modèle de base avec la quantification 4-bit (load_in_4bit=True), ce qui est essentiel pour QLoRA. Nous configurons ensuite les paramètres de LoRA (r, lora_alpha, lora_dropout) et appliquons ces adaptations au modèle. Le tokenizer est également initialisé, avec un padding token pour gérer les séquences de différentes longueurs.
from transformers import AutoModelForCausalLM, AutoTokenizer, TrainingArguments
from peft import LoraConfig, get_peft_model, prepare_model_for_kbit_training
import torch
# Définir le modèle de base (exemple, utiliser un modèle 2026 comme Llama 3 ou Mistral-Next)
model_name = "meta-llama/Llama-2-7b-hf" # Remplacer par un modèle plus récent si disponible
# Charger le tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.pad_token = tokenizer.eos_token # Important pour les LLM causaux
tokenizer.padding_side = "right"
# Charger le modèle en 4 bits pour QLoRA
model = AutoModelForCausalLM.from_pretrained(
model_name,
load_in_4bit=True,
torch_dtype=torch.bfloat16, # Utiliser bfloat16 pour la quantification
device_map="auto"
)
model.config.use_cache = False
model.config.pretraining_tp = 1
# Préparer le modèle pour l'entraînement k-bit
model = prepare_model_for_kbit_training(model)
# Configurer LoRA
lora_config = LoraConfig(
r=8,
lora_alpha=16,
target_modules=["q_proj", "k_proj", "v_proj", "o_proj"], # Cibles typiques pour les couches d'attention
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
# Appliquer LoRA au modèle
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()

Étape 3 : Tokenisation et Entraînement
3
Définition de l’Entraîneur et Lancement
Cette dernière étape prépare les données pour l’entraînement, configure les hyperparamètres et lance le fine-tuning à l’aide de la classe Trainer de Hugging Face.
EXPLICATION DU CODE
Nous définissons une fonction pour tokeniser le dataset, en tronquant si nécessaire. Ensuite, nous configurons les arguments d’entraînement (taux d’apprentissage, nombre d’époques, taille de batch, etc.). Enfin, un Trainer est instancié avec le modèle, les arguments et le dataset, et l’entraînement est lancé. Le modèle fine-tuné peut ensuite être sauvegardé et utilisé.
from transformers import TrainingArguments, Trainer, DataCollatorForLanguageModeling
# Tokeniser le dataset
max_seq_length = 512 # Adapter à la longueur typique de vos séquences
def tokenize_function(examples):
return tokenizer(
examples["text"],
truncation=True,
max_length=max_seq_length,
padding="max_length" # Pad to max_seq_length
)
tokenized_dataset = dataset.map(tokenize_function, batched=True)
# Définir les arguments d'entraînement
training_arguments = TrainingArguments(
output_dir="./results",
num_train_epochs=3, # Généralement 1-5 pour le fine-tuning
per_device_train_batch_size=4, # Ajuster selon la mémoire GPU
gradient_accumulation_steps=2, # Simule un batch size de 8 (4*2)
optim="paged_adamw_8bit", # Optimiseur adapté pour QLoRA
save_strategy="epoch",
logging_dir="./logs",
logging_steps=10,
learning_rate=2e-4, # Taux d'apprentissage typique pour LoRA
fp16=False, # Utiliser True si votre GPU le supporte et si bfloat16 n'est pas utilisé
bf16=True, # Utiliser bfloat16 si votre GPU le supporte (NVIDIA Ampere ou plus récent)
group_by_length=True,
lr_scheduler_type="cosine",
warmup_ratio=0.03,
report_to="none" # Pour désactiver le reporting par défaut à W&B si non configuré
)
# Data collator
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False)
# Initialiser le Trainer
trainer = Trainer(
model=model,
train_dataset=tokenized_dataset,
args=training_arguments,
data_collator=data_collator,
)
# Lancer l'entraînement
trainer.train()
# Sauvegarder le modèle LoRA fine-tuné
trainer.save_model("./fine_tuned_model_lora")
# Pour fusionner les adaptateurs LoRA avec le modèle de base et le sauvegarder
# from peft import PeftModel
# base_model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.float16, device_map="auto")
# model = PeftModel.from_pretrained(base_model, "./fine_tuned_model_lora")
# model = model.merge_and_unload()
# model.save_pretrained("./merged_fine_tuned_model")
# tokenizer.save_pretrained("./merged_fine_tuned_model")
POINT CLÉ
Le fine-tuning avec Hugging Face et PEFT est un processus structuré : préparation des données, chargement du modèle avec quantification et LoRA, puis entraînement avec des hyperparamètres optimisés. La sauvegarde des adaptateurs LoRA est rapide et efficace.
CONCLUSION