

RÉSUMÉ
Edge Computing en 2026 : Au-delà du Cloud, les enjeux pour les développeurs
Analyse approfondie de l’Edge Computing en 2026, ses distinctions avec le Cloud et son impact sur les compétences des développeurs.
Keywords: Edge Computing, développement Edge, IoT
TABLE DES MATIÈRES
1 Contexte et Introduction : L’Ère de l’Intelligence Distribuée
2 Edge Computing vs. Cloud Computing : Une Synergie Essentielle
3 Les Enjeux Techniques et Opérationnels de l’Edge en 2026
4 Le Rôle Crucial du Développeur dans l’Écosystème Edge
5 Application Pratique : Déployer une Application ML Simple sur un Nœud Edge
6 Perspectives d’Avenir et Tendances pour 2026 et au-delà
CONTEXTE
1. Contexte et Introduction : L’Ère de l’Intelligence Distribuée
L’année 2026 marque un tournant décisif dans l’évolution des architectures informatiques. Alors que le Cloud Computing a dominé la dernière décennie, centralisant les ressources et les services, une nouvelle étoile monte à l’horizon : l’Edge Computing. Ce paradigme, qui consiste à rapprocher le traitement des données de leur source de production, n’est plus une simple option, mais une nécessité impérieuse face à l’explosion des données générées par l’Internet des Objets (IoT) et l’impératif de réactivité en temps réel.
Le Cloud a prouvé sa valeur pour la scalabilité, le stockage massif et l’analyse de données non urgentes. Cependant, il rencontre des limites inhérentes lorsqu’il s’agit de gérer des scénarios où la latence est critique, la bande passante limitée ou la confidentialité des données primordiale. Imaginez un véhicule autonome qui doit prendre une décision en une fraction de seconde, ou une usine intelligente dont les robots doivent réagir instantanément à un imprévu. Dans ces contextes, envoyer toutes les données au Cloud pour traitement et attendre une réponse est tout simplement inenvisageable. C’est là que l’Edge Computing entre en jeu, offrant une puissance de calcul décentralisée, plus proche de l’action.
L’émergence des réseaux 5G, avec leur faible latence et leur capacité de bande passante élevée, agit comme un catalyseur puissant pour l’adoption de l’Edge Computing. La 5G ne se contente pas de connecter plus d’appareils ; elle permet de créer des réseaux privés et des « tranches » dédiées (network slicing) qui sont parfaites pour les applications Edge nécessitant une performance garantie. En 2026, cette convergence technologique transforme radicalement la manière dont les applications sont conçues, déployées et gérées, ouvrant de vastes opportunités pour les développeurs.
« L’Edge Computing n’est pas une simple évolution, mais une révolution qui redéfinit l’architecture même de l’informatique, plaçant l’intelligence là où elle est la plus nécessaire : au plus près de la source des données. »
— Kwontenu, Expert en Technologies Distribuées
POINT CLÉ
L’Edge Computing est devenu indispensable en 2026 pour adresser les défis de latence, de bande passante et de confidentialité que le Cloud seul ne peut résoudre, notamment avec l’explosion de l’IoT et l’arrivée de la 5G.
ANALYSE COMPARATIVE
2. Edge Computing vs. Cloud Computing : Une Synergie Essentielle, Pas une Substitution
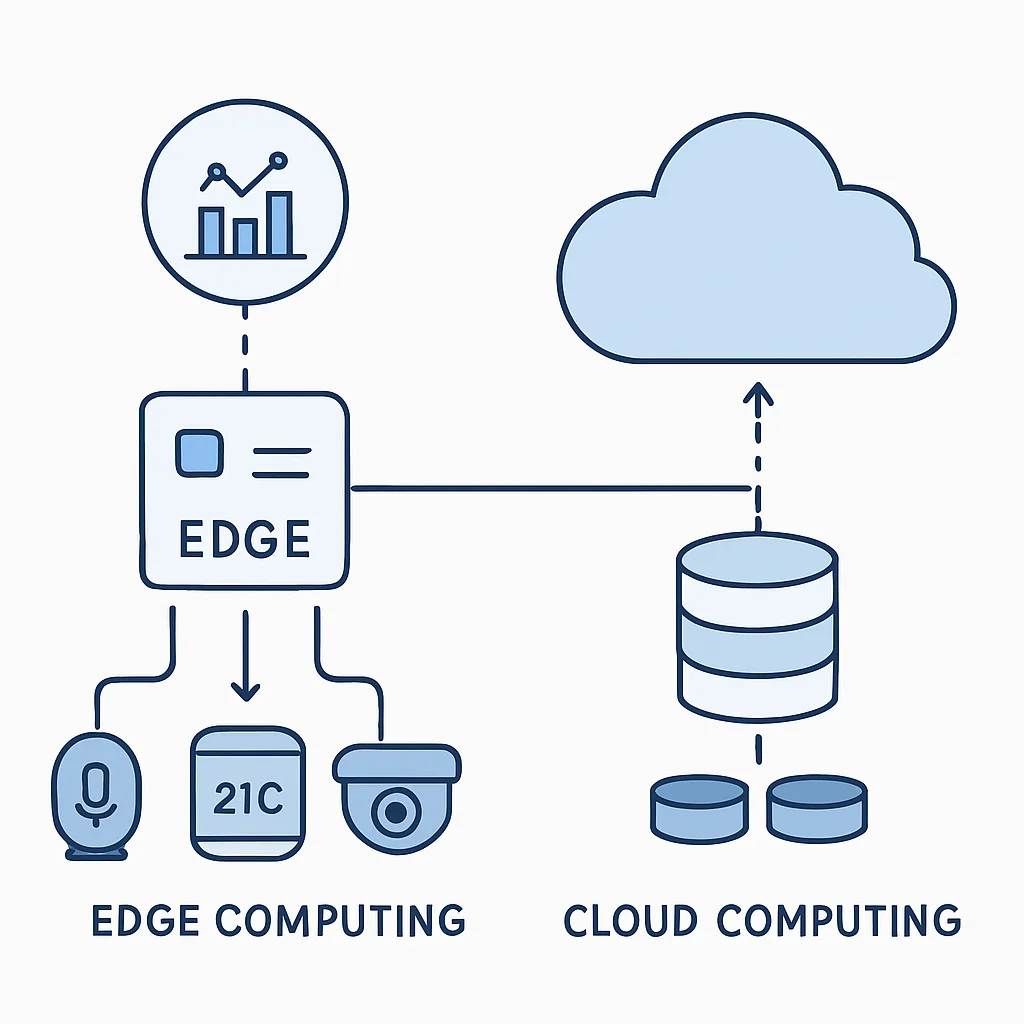
Il est crucial de comprendre que l’Edge Computing n’est pas destiné à remplacer le Cloud, mais plutôt à le compléter. Il s’agit d’une architecture distribuée où les forces de chaque modèle sont exploitées de manière optimale. Le Cloud reste la colonne vertébrale pour le stockage à long terme, l’analyse Big Data, la formation de modèles d’apprentissage automatique complexes et la gestion centralisée d’infrastructures massives. L’Edge, quant à lui, excelle dans les traitements immédiats, les inférences de modèles ML, la filtration des données et les interactions en temps réel.
| Caractéristique | Edge Computing | Cloud Computing |
|---|---|---|
| Latence | Très faible (millisecondes) | Élevée (dizaines à centaines de millisecondes) |
| Bande passante | Réduit les besoins de bande passante vers le Cloud | Nécessite une bande passante élevée pour le transfert de données |
| Traitement des données | Traitement en temps réel, inférence ML | Analyse Big Data, entraînement ML, stockage massif |
| Sécurité/Confidentialité | Données sensibles traitées localement, réduction des risques de transmission | Dépend des mesures de sécurité du fournisseur Cloud, données potentiellement exposées en transit |
| Coût | Investissement initial en matériel, réduction des coûts de bande passante et de Cloud à long terme | Modèle de paiement à l’usage, coûts élevés pour le transfert et le stockage de gros volumes de données |
| Cas d’usage typiques | Véhicules autonomes, usines intelligentes, réalité augmentée/virtuelle, surveillance en temps réel | Applications web/mobiles, SaaS, CRM, ERP, bases de données massives, data warehousing |
Cette complémentarité donne naissance à des architectures hybrides, où les données sont collectées à la périphérie, traitées localement pour les décisions immédiates, puis filtrées et agrégées avant d’être envoyées au Cloud pour une analyse plus approfondie ou un stockage à long terme. Cette approche permet de tirer parti du meilleur des deux mondes : la réactivité de l’Edge et la puissance d’analyse du Cloud.
Des exemples concrets illustrent cette synergie. Dans l’agriculture intelligente, des capteurs Edge collectent des données sur l’humidité du sol, la température, et la santé des cultures. Ces données sont analysées en temps réel sur des mini-serveurs Edge pour optimiser l’irrigation et la fertilisation sans délai. Seules les anomalies ou les résumés agrégés sont ensuite transmis au Cloud pour des analyses saisonnières et l’amélioration des modèles prédictifs. De même, dans le commerce de détail, les caméras intelligentes Edge peuvent détecter les ruptures de stock ou les comportements clients suspects en temps réel, tandis que le Cloud consolide les données de tous les magasins pour des stratégies marketing globales.
POINT CLÉ
L’Edge et le Cloud sont complémentaires. L’Edge gère la réactivité et la confidentialité locale, tandis que le Cloud assure la scalabilité, le stockage de masse et l’analyse globale. Une architecture hybride est souvent la solution la plus efficace.
« L’avenir de l’informatique réside dans un équilibre intelligent entre la centralisation du Cloud et la décentralisation de l’Edge, optimisant chaque charge de travail pour sa localisation et ses exigences spécifiques. »
— Vision stratégique de l’industrie technologique en 2026
DÉFIS & SOLUTIONS
3. Les Enjeux Techniques et Opérationnels de l’Edge en 2026
Déployer et maintenir des infrastructures Edge à grande échelle présente des défis uniques qui dépassent souvent ceux du Cloud traditionnel. Les développeurs et architectes doivent être conscients de ces obstacles pour concevoir des solutions robustes et évolutives.
3.1. Gestion et Orchestration des Dispositifs Edge
Avec des milliers, voire des millions de dispositifs Edge dispersés géographiquement, la gestion devient un casse-tête logistique. Mettre à jour des logiciels, appliquer des correctifs de sécurité, surveiller l’état de santé des appareils et collecter des logs à distance sont des opérations complexes. Les solutions modernes s’appuient sur la conteneurisation (Docker, Podman) et l’orchestration légère (Kubernetes Edge comme K3s, MicroK8s, ou KubeEdge) pour standardiser les déploiements et simplifier les mises à jour. Ces outils permettent de traiter les nœuds Edge comme des extensions du Cloud, avec une gestion centralisée mais une exécution distribuée.
PROBLÈME 01
Déploiement et mise à jour de milliers de nœuds Edge
Maintenir des logiciels à jour et appliquer des correctifs de sécurité sur un parc hétérogène de dispositifs Edge disséminés est une tâche ardue et sujette aux erreurs manuelles.
SOLUTION — Utilisation de conteneurs et d’orchestrateurs légers
Standardiser les applications avec des conteneurs Docker et les déployer via des plateformes d’orchestration Edge comme KubeEdge permet une gestion centralisée des mises à jour et des configurations, réduisant ainsi la complexité opérationnelle et les risques d’erreurs.
EXPLICATION DU CODE
Cet exemple montre un fichier de déploiement Kubernetes simplifié pour un nœud Edge. Il spécifie une application conteneurisée (ici, une application de traitement d’images) et les ressources nécessaires. Les plateformes Edge-Kubernetes peuvent ensuite déployer et gérer ce conteneur à distance sur des appareils Edge.
apiVersion: apps/v1
kind: Deployment
metadata:
name: image-processor-edge
spec:
replicas: 1
selector:
matchLabels:
app: image-processor
template:
metadata:
labels:
app: image-processor
spec:
nodeSelector:
kubernetes.io/hostname: edge-device-001 # Cible un nœud Edge spécifique
containers:
- name: processor
image: kwontenu/edge-image-processor:1.0.0
resources:
limits:
cpu: "500m"
memory: "256Mi"
requests:
cpu: "200m"
memory: "128Mi"
volumeMounts:
- name: data-volume
mountPath: /data
volumes:
- name: data-volume
hostPath:
path: /var/lib/edge-data
type: DirectoryOrCreate
3.2. Sécurité et Confidentialité des Données
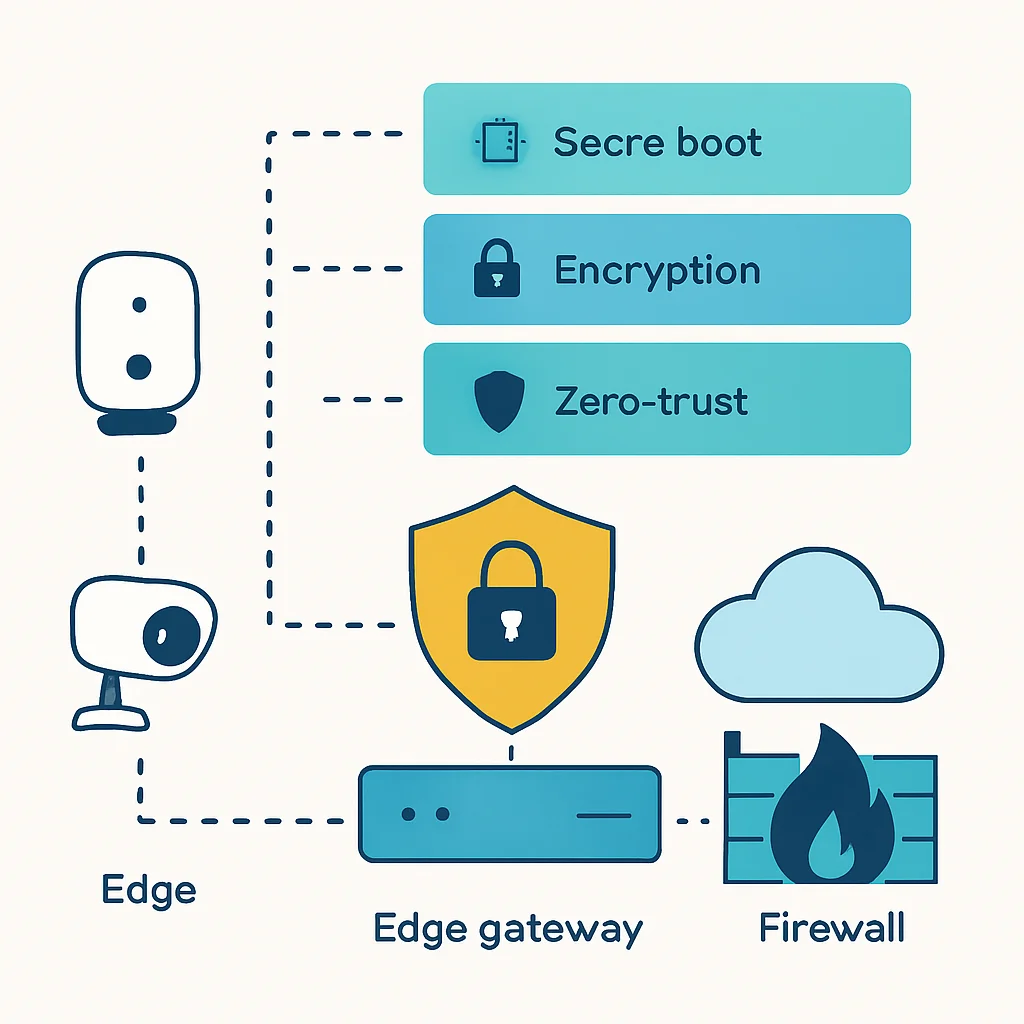
Chaque nœud Edge représente un point d’entrée potentiel pour les cyberattaques. L’environnement Edge est souvent moins sécurisé physiquement que les centres de données Cloud, et les appareils peuvent être plus vulnérables. La sécurité doit être pensée dès la conception : démarrage sécurisé (secure boot), chiffrement des données au repos et en transit, authentification forte des appareils, et implémentation de principes de « zero trust ». De plus, la gestion de la confidentialité est cruciale, surtout lorsque des données personnelles ou sensibles sont traitées localement, nécessitant des mécanismes d’anonymisation ou de pseudonymisation à la source.
Les réglementations telles que le RGPD en Europe ou le CCPA aux États-Unis imposent des contraintes strictes sur le traitement des données. L’Edge Computing peut paradoxalement aider à la conformité en gardant les données sensibles localement, réduisant ainsi le transfert vers des juridictions potentiellement différentes. Cependant, il exige une vigilance accrue sur la gestion des accès et des journaux d’audit sur chaque nœud.
3.3. Contraintes Matérielles et Énergétiques
Les dispositifs Edge sont souvent des appareils aux ressources limitées en termes de puissance de calcul, de mémoire et de stockage. Ils peuvent également fonctionner sur batterie ou dans des environnements où la consommation d’énergie est une contrainte majeure. Cela implique de développer des applications optimisées, utilisant des systèmes d’exploitation légers, des algorithmes efficaces et, de plus en plus, du matériel spécialisé comme les accélérateurs d’IA (GPUs embarqués, NPUs, ASICs) pour l’inférence de modèles d’apprentissage automatique. La sélection des bons outils et frameworks, capables de fonctionner avec des empreintes mémoire et CPU minimales, est essentielle.
POINT CLÉ
Les principaux défis de l’Edge Computing incluent la gestion distribuée, la sécurité des données dans des environnements hétérogènes et les contraintes de ressources matérielles. Les solutions passent par la conteneurisation, les architectures zero-trust et l’optimisation logicielle/matérielle.
« La transition vers l’Edge exige une refonte des approches de développement, en privilégiant l’efficacité, la résilience et la sécurité dès les premières étapes de conception. »
— Le guide de l’architecture distribuée pour 2026
DÉVELOPPEMENT EDGE
4. Le Rôle Crucial du Développeur dans l’Écosystème Edge
L’Edge Computing remodèle profondément le paysage du développement logiciel. Les développeurs ne se contentent plus d’écrire du code pour des environnements Cloud illimités ; ils doivent désormais penser à l’optimisation des ressources, à la résilience hors ligne et à la sécurité intrinsèque. Ce changement crée de nouvelles opportunités et exige l’acquisition de compétences spécifiques.
4.1. Compétences Requises
Pour exceller dans le développement Edge en 2026, plusieurs domaines de compétences sont devenus essentiels :
- Systèmes Distribués et Réseaux : Une compréhension approfondie des architectures distribuées, des protocoles de communication (MQTT, CoAP, HTTP/2) et des défis liés à la connectivité intermittente est fondamentale.
- Langages de Programmation : Des langages performants comme Python (pour sa simplicité et ses bibliothèques ML), Go (pour sa concurrence et sa légèreté), Rust (pour la sécurité et la performance système) et C++ (pour le contrôle bas niveau et l’embarqué) sont prédominants.
- Conteneurisation et Orchestration : Maîtriser Docker et des orchestrateurs Kubernetes légers (K3s, MicroK8s) est crucial pour le déploiement et la gestion des applications Edge.
- Apprentissage Automatique embarqué (TinyML) : La capacité à optimiser et déployer des modèles ML sur des appareils à faibles ressources, en utilisant des frameworks comme TensorFlow Lite ou ONNX Runtime, est une compétence très recherchée.
- Sécurité : Une connaissance des bonnes pratiques de sécurité (chiffrement, authentification, gestion des vulnérabilités) est impérative, car chaque nœud Edge est une cible potentielle.
4.2. Outils et Frameworks pour le Développement Edge
Le marché des outils Edge est en pleine effervescence. Les géants du Cloud proposent leurs propres solutions pour étendre leurs services à la périphérie :
- AWS IoT Greengrass : Permet d’exécuter des fonctions Lambda, des conteneurs Docker et des modèles ML directement sur les appareils Edge.
- Azure IoT Edge : Offre la possibilité de déployer des charges de travail Cloud (modules conteneurisés) sur des appareils Edge, avec une gestion centralisée via Azure IoT Hub.
- Google Cloud IoT Edge : Intègre des capacités de ML Edge avec TensorFlow Lite et une gestion des appareils.
En dehors des offres Cloud, des projets open source gagnent en popularité :
- KubeEdge : Un projet CNCF qui étend les capacités d’orchestration de Kubernetes aux nœuds Edge.
- EdgeX Foundry : Une plateforme d’interopérabilité pour l’IoT Edge, offrant un cadre de services micro-basés pour la collecte, le traitement et l’exportation des données.

4.3. Cas d’Usage et Opportunités
Les opportunités de carrière et d’innovation dans l’Edge Computing sont immenses. Voici quelques domaines où les développeurs peuvent faire la différence :
Opportunités Clés en Développement Edge
Maintenance Prédictive : Développer des modèles ML pour anticiper les pannes d’équipements industriels, réduisant les temps d’arrêt de 15% en moyenne.
Optimisation Logistique : Créer des systèmes de suivi et d’optimisation de flotte en temps réel, améliorant l’efficacité des livraisons de 10-20%.
Villes Intelligentes : Concevoir des solutions pour la gestion du trafic, la surveillance de la qualité de l’air ou l’éclairage public adaptatif, avec des réductions de consommation énergétique pouvant atteindre 30%.
Santé Connectée : Développer des dispositifs portables qui analysent les données vitales localement pour des alertes immédiates, améliorant la réactivité des soins.
Sécurité et Surveillance : Implémenter des systèmes de reconnaissance faciale ou d’analyse comportementale qui traitent les données vidéo localement pour garantir la confidentialité et la rapidité.
POINT CLÉ
Les développeurs Edge doivent maîtriser les systèmes distribués, les langages performants, la conteneurisation et l’apprentissage automatique embarqué. Les outils des fournisseurs Cloud et les frameworks open source sont des atouts majeurs pour exploiter les nombreuses opportunités de l’Edge.
« Le développeur Edge de 2026 est un ingénieur polyvalent, capable de jongler entre les contraintes matérielles, les exigences de performance et les impératifs de sécurité, tout en créant des solutions innovantes au plus près de l’action. »
— Profil idéal pour l’innovation Edge
GUIDE PRATIQUE
5. Application Pratique : Déployer une Application ML Simple sur un Nœud Edge
Pour illustrer concrètement le développement Edge, nous allons parcourir les étapes de déploiement d’une application d’inférence d’apprentissage automatique simple sur un nœud Edge typique, comme un Raspberry Pi ou un mini-PC industriel. L’objectif est de classifier des images capturées localement sans envoyer chaque image au Cloud.
1
Préparation de l’Environnement Edge
Nous partons du principe que vous disposez d’un appareil Edge (ex: Raspberry Pi 4 avec Raspberry Pi OS) avec Python 3 installé. Installez les bibliothèques nécessaires : TensorFlow Lite Runtime pour l’inférence et OpenCV pour la capture d’images.
EXPLICATION DU CODE
Ces commandes installent les paquets Python requis. tflite-runtime est la version légère de TensorFlow pour l’exécution sur Edge, et opencv-python est pour la manipulation d’images et l’accès à la caméra.
pip install tflite-runtime
pip install opencv-python numpy2
Acquisition d’un Modèle TensorFlow Lite
Utilisez un modèle pré-entraîné ou entraînez le vôtre et convertissez-le au format .tflite. Pour cet exemple, nous allons utiliser un modèle MobileNet V2 quantifié, optimisé pour les appareils Edge. Téléchargez-le et placez-le dans le répertoire de votre projet.
Vous pouvez trouver des modèles sur le TensorFlow Lite Model Garden. Par exemple, téléchargez mobilenet_v2_1.0_224_quant.tflite et son fichier labels.txt.
3
Code de l’Application d’Inférence Edge
Voici un script Python qui initialise le modèle TensorFlow Lite, capture une image depuis une webcam (ou un fichier), effectue l’inférence et affiche le résultat.
EXPLICATION DU CODE
Ce script edge_inference.py charge un modèle TensorFlow Lite et ses étiquettes. Il capture une image, la pré-traite pour correspondre aux attentes du modèle (redimensionnement, normalisation), exécute l’inférence et affiche la classe prédite avec sa probabilité. Le processus est entièrement local, minimisant la latence et la consommation de bande passante.
import numpy as np
import cv2
import tflite_runtime.interpreter as tflite
import time
# --- Configuration ---
MODEL_PATH = 'mobilenet_v2_1.0_224_quant.tflite'
LABELS_PATH = 'labels.txt'
INPUT_SHAPE = (224, 224) # Taille d'entrée attendue par le modèle
# --- Fonctions utilitaires ---
def load_labels(path):
with open(path, 'r') as f:
return [line.strip() for line in f.readlines()]
def preprocess_image(image, input_shape):
# Redimensionner l'image à la taille attendue par le modèle
resized_image = cv2.resize(image, input_shape)
# Convertir en float32 et normaliser si nécessaire (dépend du modèle)
# Pour les modèles quantifiés, les valeurs sont généralement entre 0 et 255
input_data = np.expand_dims(resized_image, axis=0)
return input_data
# --- Initialisation de l'interpréteur TFLite ---
interpreter = tflite.Interpreter(model_path=MODEL_PATH)
interpreter.allocate_tensors()
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
# Vérifier si le modèle est quantifié (type uint8) ou float32
input_mean = 127.5
input_std = 127.5
if input_details[0]['dtype'] == np.uint8:
floating_model = False
else:
floating_model = True
# Charger les labels
labels = load_labels(LABELS_PATH)
print(f"Modèle chargé : {MODEL_PATH}")
print(f"Labels chargés : {LABELS_PATH}")
# --- Capture d'image (depuis webcam ou fichier) ---
# Pour une webcam :
cap = cv2.VideoCapture(0) # 0 pour la webcam par défaut
if not cap.isOpened():
print("Erreur: Impossible d'ouvrir la webcam. Essai de charger une image statique.")
# Si la webcam ne fonctionne pas, charger une image de test
image_path = "test_image.jpg" # Assurez-vous d'avoir une image test_image.jpg
try:
frame = cv2.imread(image_path)
if frame is None:
raise FileNotFoundError(f"L'image {image_path} n'a pas été trouvée.")
print(f"Image chargée depuis {image_path}")
except FileNotFoundError as e:
print(e)
print("Veuillez vérifier votre webcam ou fournir une image de test.")
exit()
else:
ret, frame = cap.read()
if not ret:
print("Erreur: Impossible de lire l'image de la webcam.")
exit()
print("Image capturée depuis la webcam.")
cap.release() # Libérer la webcam après capture
# --- Prétraitement de l'image ---
input_data = preprocess_image(frame, INPUT_SHAPE)
# Si le modèle attend des flottants, normaliser les données
if floating_model:
input_data = (np.float32(input_data) - input_mean) / input_std
# --- Exécution de l'inférence ---
interpreter.set_tensor(input_details[0]['index'], input_data)
start_time = time.time()
interpreter.invoke()
end_time = time.time()
output_data = interpreter.get_tensor(output_details[0]['index'])
results = np.squeeze(output_data)
# --- Post-traitement des résultats ---
if floating_model:
probabilities = results # Pour les modèles flottants, les résultats sont déjà des probabilités
else:
# Pour les modèles quantifiés, les résultats sont des entiers qui doivent être déquantifiés
scale, zero_point = output_details[0]['quantization_parameters']['scales'], output_details[0]['quantization_parameters']['zero_points']
probabilities = (results - zero_point) * scale
# Convertir en probabilités (softmax)
exp_results = np.exp(probabilities - np.max(probabilities))
softmax_probabilities = exp_results / np.sum(exp_results)
top_k = softmax_probabilities.argsort()[-5:][::-1] # Top 5 résultats
print('\n--- Résultats de l\'inférence ---')
print(f"Temps d'inférence : {(end_time - start_time) * 1000:.2f} ms")
for i in top_k:
if floating_model:
print(f'{labels[i]}: {softmax_probabilities[i]:.2f}')
else:
print(f'{labels[i]}: {softmax_probabilities[i]:.2f}')
# Afficher l'image capturée avec le résultat (optionnel)
cv2.imshow('Image Edge Processed', frame)
cv2.waitKey(0)
cv2.destroyAllWindows()
4
Exécution et Optimisation
Exécutez le script sur votre appareil Edge. Vous devriez voir le temps d’inférence (généralement quelques dizaines à centaines de millisecondes) et les classes prédites. Pour optimiser davantage, vous pouvez utiliser des accélérateurs matériels (comme le Coral Edge TPU de Google) si votre appareil en est équipé. Ces accélérateurs peuvent réduire le temps d’inférence à des millisecondes uniques pour certains modèles.
EXPLICATION DU CODE
Pour utiliser un Edge TPU, vous devez installer des paquets supplémentaires et modifier l’initialisation de l’interpréteur TFLite. Le paramètre experimental_delegates permet de déléguer le calcul au matériel spécialisé.
# Installation pour Edge TPU
# pip install python3-tflite-runtime # Si non déjà installé
# pip install edgetpu-tflite-runtime # Ou la version spécifique de l'API Coral
# Modification du code Python pour utiliser Edge TPU
# import tflite_runtime.interpreter as tflite
# from tflite_runtime.interpreter import load_delegate # Pour Coral Edge TPU
# interpreter = tflite.Interpreter(
# model_path=MODEL_PATH,
# experimental_delegates=[load_delegate('libedgetpu.so.1')]
# )
# interpreter.allocate_tensors()
# ... le reste du code est le même ...
POINT CLÉ
Déployer une application ML sur Edge implique de charger un modèle optimisé (TFLite), de prétraiter les données localement et d’exécuter l’inférence directement sur le dispositif. L’utilisation d’accélérateurs matériels comme l’Edge TPU peut drastiquement améliorer les performances.
PERSPECTIVES
6. Perspectives d’Avenir et Tendances pour 2026 et au-delà
L’Edge Computing est une technologie en constante évolution, et 2026 n’est qu’une étape dans sa maturation. Plusieurs tendances clés façonneront son avenir et ouvriront de nouvelles frontières pour l’innovation.
L’intégration plus poussée avec la 5G et la future 6G est primordiale. La 5G a déjà commencé à réduire la latence et à augmenter la bande passante, mais la 6G promet des capacités encore plus extrêmes, permettant des applications Edge ultra-fiables et à très faible latence, comme la chirurgie à distance ou les réseaux de capteurs massifs pour la surveillance environnementale à l’échelle planétaire. La capacité de la 5G à créer des réseaux privés et des « tranches » dédiées pour des cas d’utilisation spécifiques va également simplifier le déploiement et la gestion des infrastructures Edge complexes.
L’intelligence artificielle à la périphérie (TinyML) continuera de se miniaturiser, permettant à des modèles ML sophistiqués de fonctionner sur des microcontrôleurs avec des contraintes énergétiques et de calcul extrêmement faibles. Cela ouvrira la voie à des capteurs « intelligents » autonomes, capables de prendre des décisions sans aucune connectivité externe, dans des domaines comme les dispositifs médicaux implantables ou les systèmes de surveillance agricole en zones reculées. On estime que d’ici 2028, plus de 75% des nouvelles applications IoT incluront des capacités d’IA Edge.
La décentralisation de l’Edge, potentiellement via des technologies de blockchain ou de registres distribués (DLT), pourrait émerger pour créer des réseaux Edge plus résilients et sécurisés. Imaginez des réseaux de nœuds Edge qui s’authentifient et partagent des ressources de manière décentralisée, sans point de contrôle unique. Cela pourrait renforcer la confidentialité et la robustesse des systèmes.
Enfin, l’Edge Quantique, bien que plus lointain, est une perspective fascinante. À mesure que l’informatique quantique progresse, des processeurs quantiques miniaturisés pourraient un jour être intégrés à la périphérie, permettant des calculs d’une complexité inégalée pour des problèmes spécifiques, là où la latence est la plus critique.
POINT CLÉ
L’avenir de l’Edge Computing est étroitement lié à la 5G/6G, à la miniaturisation de l’IA (TinyML), aux architectures décentralisées et, à plus long terme, à l’informatique quantique. Ces évolutions promettent des applications toujours plus autonomes et réactives.
« L’Edge Computing est bien plus qu’une tendance ; c’est une feuille de route pour un avenir où l’intelligence sera omniprésente, réactive et profondément intégrée à notre environnement physique. »
— Kwontenu, Anticipation technologique
Foire Aux Questions sur l’Edge Computing
Q. Quelle est la principale différence entre l’Edge Computing et le Cloud Computing ?
La principale différence réside dans la localisation du traitement des données. L’Edge Computing traite les données à la périphérie du réseau, près de la source de génération, tandis que le Cloud Computing les traite dans des centres de données centralisés et distants. L’Edge réduit la latence et la bande passante, le Cloud offre une scalabilité massive et une puissance de calcul supérieure pour l’analyse globale.
Q. Pourquoi l’Edge Computing est-il devenu si important en 2026 ?
L’Edge Computing est devenu crucial en 2026 en raison de l’explosion des appareils IoT, de la nécessité de traiter les données en temps réel pour des applications critiques (véhicules autonomes, usines intelligentes) et de l’avènement des réseaux 5G qui facilitent la connectivité périphérique. Il répond aux limites du Cloud en termes de latence, de bande passante et de confidentialité.
Q. Quelles compétences un développeur doit-il acquérir pour travailler dans l’Edge Computing ?
Les développeurs Edge doivent maîtriser les systèmes distribués, les protocoles réseau (MQTT, CoAP), les langages performants (Python, Go, Rust), la conteneurisation (Docker, Kubernetes Edge), l’apprentissage automatique embarqué (TinyML, TensorFlow Lite) et les bonnes pratiques de sécurité pour les environnements contraints.
Q. L’Edge Computing remplace-t-il le Cloud Computing ?
Non, l’Edge Computing ne remplace pas le Cloud Computing, mais le complète. Ils fonctionnent en synergie au sein d’architectures hybrides. L’Edge gère les traitements immédiats et la filtration des données, tandis que le Cloud est utilisé pour le stockage à long terme, l’analyse Big Data et l’entraînement de modèles ML complexes.
Q. Quels sont les principaux défis de sécurité dans l’Edge Computing ?
Les défis de sécurité incluent une surface d’attaque accrue due au grand nombre de dispositifs, des environnements physiques moins sécurisés que les data centers, et la gestion de la confidentialité des données sensibles traitées localement. Les solutions impliquent le démarrage sécurisé, le chiffrement, l’authentification forte des appareils et l’adoption de principes de « zero trust ».
Merci de votre lecture !
L’Edge Computing est sans aucun doute l’une des tendances technologiques les plus impactantes de 2026. Nous espérons que cette analyse vous aura éclairé sur ses enjeux et opportunités.
Des questions, des commentaires ou des expériences à partager sur l’Edge Computing ? N’hésitez pas à laisser un message ci-dessous, nous serions ravis d’échanger avec vous !